
What is the first thing that comes to your mind upon hearing the word ‘Airflow’? Data engineering, right? For good reason, I suppose. You are likely to find Airflow mentioned in every other blog post that talks about data engineering.
Apache Airflow is a workflow management platform. To oversimplify, you can think of it as cron, but on steroids! It was started in October 2014 by Maxime Beauchemin at Airbnb. From the very first commit, Airflow was open source. Less than a year later, it was moved into the Airbnb Github. Since then, it has become a vital part of the data engineering ecosystem.
We have been using Airflow to move data across our internal systems for more than a year, over the course of which we have created a lot of ETL (Extract-Transform-Load) pipelines. In this post, we’ll talk about one of these pipelines in detail and show you the set-up steps.
Note: We will not be going through how to set up Airflow. You can check out a great blog from Clairvoyant for that.
Why use Airflow?
- Dependency Management: A workflow can be defined as a Directed Acyclic Graph (DAG). Airflow will make sure that the defined tasks are executed one after the other, managing the dependencies between tasks.
- Extensible: Airflow offers a variety of Operators, which are the building blocks of a workflow. One example is the PythonOperator, which you can use to write custom Python code that will run as a part of your workflow.
- Scalable: Celery, which is a distributed task queue, can be used as an Executor to scale your workflow’s execution.
- Open Source: It is under incubation at the Apache Software Foundation, which means it is being actively maintained.
IDSP: The disease data source
Even though open data portals are cropping up across multiple domains, working with the datasets they provide is difficult. In our bid to identify and help prevent disease outbreaks, we came across one such difficult data source.
The Ministry of Health and Family Affairs (MHRD) runs the Integrated Disease Surveillance Programme (IDSP) scheme, which identifies disease outbreaks at the sub-district & village level across India. Under this scheme, the MHRD releases weekly outbreak data as a PDF document.
PDFs are notorious for being hard to scrape and incorporate in data science workflows, but just wait till you see the IDSP PDFs. It may look like the data in them is in a nice table format, but they’ve changed the table formatting over the years and may continue to do so. We’ve also encountered glitches in the document like different tables being joined together, tables flowing out of the page and even tables within tables!
Setting up the ETL pipeline
No brownie points for figuring out the steps involved in our pipeline. We (E)xtract the PDFs from the IDSP website, (T)ransform the PDFs into CSVs and (L)oad this CSV data into a store.
Conventions
Let us set up some conventions now, because without order, anarchy would ensue! Each Directed Acyclic Graph should have a unique identifier. We can use an ID, which describes what our DAG is doing, plus a version number. Let us name our DAG idsp_v1.
Note: We borrowed this naming convention from the Airflow “Common Pitfalls” documentation. It comes in handy when you have to change the start date and schedule interval of a DAG, while preserving the scheduling history of the old version. Make sure you check out this link for other common pitfalls.
We will also define a base directory where data from all the DagRuns will be kept. What is a DagRun, you ask? It is just an instance of your DAG in time. We will also create a new directory for each DagRun.
Here’s a requirements.txt file which you can use to install the dependencies.
How to DAG
In Airflow, DAGs are defined as Python files. They have to be placed inside the dag_folder, which you can define in the Airflow configuration file. Based on the ETL steps we defined above, let’s create our DAG.
We will define three tasks using the Airflow PythonOperator. You need to pass your Python functions containing the task logic to each Operator using the python_callable keyword argument. Define these as dummy functions in a utils.py file for now. We’ll look at each one later.
We will also link them together using the set_downstream methods. This will define the order in which our tasks get executed. Observe how we haven’t defined the logic that will run inside the tasks, but our DAG is ready to run!
Have a look at the DAG file. We have set the schedule_interval to 0 0 * * 2. Yes, you guessed it correctly — it’s a cron string.This means that our DAG will run every Tuesday at 12 AM. Airflow scheduling can be a bit confusing, so we suggest you check out the Airflow docs to understand how it works.
We have also set provide_context to True since we want Airflow to pass the DagRun’s context (think metadata, like the dag_id, execution_date etc.) into our task functions as keyword arguments.
Note: We’ll use execution_date (which is a Python datetime object) from the context Airflow passes into our function to create a new directory, like we discussed above, to store the DagRun’s data.
At this point, you can go ahead and create a DAG run by executing airflow trigger_dag idsp_v1 on the command line. Make sure you go to the Airflow UI and unpause the DAG before creating a DagRun. The DagRun should be a success since our tasks are just dummy functions.
Now that we have our DAG file ready, let’s look at the logic that will run inside our tasks.
Note: Everything you print to stdout inside the function passed to the PythonOperator will be viewable on the Airflow UI. Just click on View Log in the respective operator’s DAG node.
Scraping the IDSP website
A new PDF document is released almost every week (with some lag) on the IDSP website. We can’t keep scraping all the PDFs every time a new one is released. Instead, we will have to save the week number of the PDF we last scraped somewhere.
We can store this state in a CSV file in our base directory at the end of each DagRun and refer to it at the start of another. Take a look at the scraping code. There’s nothing fancy here, just your run-of-the-mill web scraping, using requests and lxml.
Note: In production, we don’t run the scraping code inside Airflow. It is run on a separate service, which can connect to REST/SOAP APIs to extract data, in addition to running these scrapers. This gives us a central place to schedule and track how data is pulled into our platform. The task logic is replaced with a call to the data export service.
Scraping the PDFs
Yay! Now that we have new PDFs, we can go about scraping them. We will use pdfminer to accomplish this.
But first, let me just point out that PDF is the worst format for tabular data. A PDF contains instructions for PDF viewers to place text in the desired font at specific X,Y coordinates on the 2D plane. It doesn’t matter if we just need to get text from of a PDF, but if we need to get tabular data with the table structure intact, it gets difficult. We use a simple heuristic here to get this data out.
First, we extract all text objects using pdfminer. A text object contains a string and a float coordinate tuple, which describes the string’s position. We then sort all these objects in increasing X and increasing Y order. We now have all these text objects in row-major format, starting from the last row. We can just group them based on their x-axis projections into different columns, discarding any objects that span multiple columns. We can drop the first and last columns since we don’t have any use for them in this post.
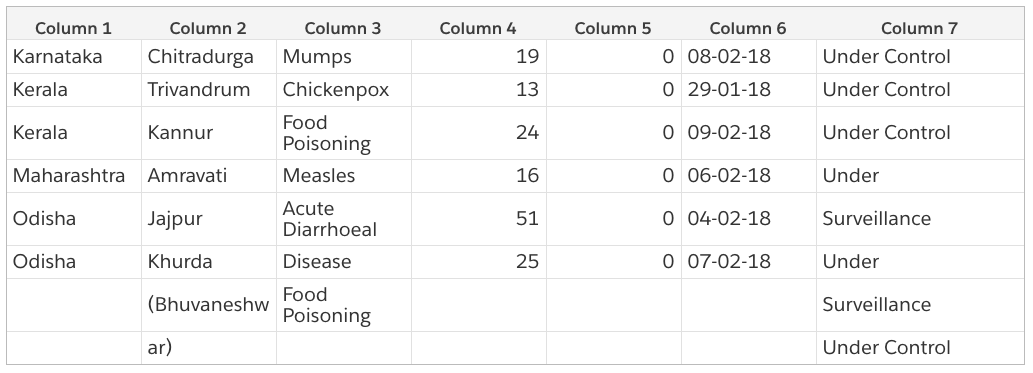
Voila, we have our table! It is still not usable though and needs some minor cleaning. We are leaving this as an exercise to you. It is easy to define some rules in code to convert the above CSV to something cleaner, like the following.
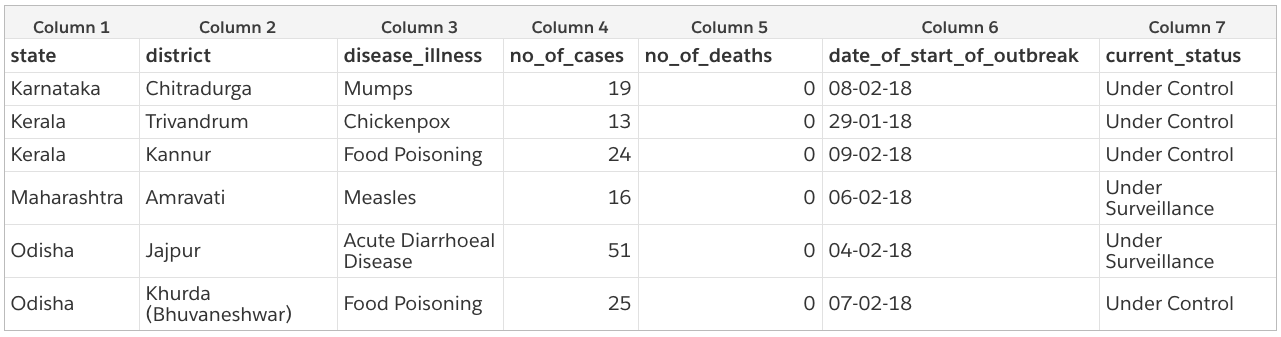
You can add this cleaning code as another PythonOperator or within the same scrape_pdf operator. If you are not comfortable with Python and want to use R instead, you can use the BashOperator to call your R script. Extensibility FTW!
Note: It is very difficult to get 100% table scraping accuracy on all types of PDF with a single tool. We can just throw various heuristics at the problem and hope for the best result. A cleaning step is usually required.
When we were in the process of preparing the IDSP dataset, using all the previous years’ PDFs, we couldn’t find any tool/library that could solve this problem. We tried many open source tools like Tabula, as well as closed source tools like PDFTables without any success.
This led us to developing our own library, which uses image recognition with a bunch of heuristics to try and solve the PDF table scraping problem. It gave us an acceptable scraping accuracy on a lot of PDF types, including the IDSP ones. Once we plugged this into our data cleaning product, Transform, we could finally convert PDF data into a fully clean CSV.
Update (5th October 2018): We released Camelot, a Python library that helps anyone extract tabular data from PDFs. You can find a version of the code provided in this blog post that uses Camelot in this Jupyter notebook.
Curating the scraped data
Now that we have a clean CSV, we can add it to our master IDSP dataset. The operator contains just a for loop, which appends page-wise CSVs to our master CSV dataset. We could’ve used pandas here, but we didn’t want to add another requirement just for this append.
Internally, our ETL pipeline doesn’t stop here though. We pass the text in the ‘Comments’ column that we dropped earlier through our entity recognition system, which gives us a list of geographies where the outbreaks happened. This is then used to send alerts to our team and clients.
Where can you go from here?
Congrats! You have a regularly updating disease outbreaks data set! Now it’s up to you to figure out how you’re gonna use it. cough predictive analytics cough. You can replace the scraping code to scrape data from any other website, write it to the run directory, plug in the PDF scraping operator (if the data you scraped is in PDF format), or plug in a bunch of your own operators to do anything 🙂
You can find the complete code repo for this exercise here.
If you do extend this DAG, do tweet at us. We’d love to hear what you did!
Seize the data!
The GitHub repository linked in this article was updated on July 5, 2019.



11 Comments
Pingback: How to Create a Workflow in Apache Airflow to Track Disease Outbreaks in India – Devops Dojo
Pingback: Airflow, Meta Data Engineering and a Data Platform for World’s Largest Democracy - Finance Crypto Community
Pingback: Announcing Camelot, a Python Library to Extract Tabular Data from PDFs (Open Source) - Industrylink360
Pingback: Deploying Apache Airflow in Azure to build and run data pipelines | Mashford's Musings
Pingback: Deploying Apache Airflow in Azure to build and run data pipelines | Blog – MusicCosMos
Pingback: Deploying Apache Airflow in Azure to build and run data pipelines
Pingback: Deploying Apache Airflow in Azure to build and run data pipelines - ILIKESQL
Pingback: Deploying Apache Airflow in Azure to build and run data pipelines | Blog | Microsoft Azure
Pingback: Deploying Apache Airflow in Azure to build and run data pipelines – Everything About Cloud Computing Technology
I have tried this code but only the scrap web works after that it gets failed and scrape pdf doesn’t work.
Can you elaborate by letting us know what error are you getting?
We also have updated the Github repository linked to this article. Hopefully, that should help.