
Sean presented a talk about how he built this app at the December 2018 edition of the Delhi userR meetup. Learn more about the meetup here, or watch his talk below.
If I told you that, according to the 2011 Census, 67% of Indian households had access to electricity, how would you evaluate that statistic? You might ask, is this a large increase over the previous Census? How does this percentage vary if we are talking about households in Uttar Pradesh as opposed to those in Andhra Pradesh? How would knowing these are urban as opposed to rural households, or SC/ST as opposed to all households, change our understanding?
When it comes to socioeconomic development data, single-number summary statistics lack much-needed context, especially in a country as diverse as India. Of course, in order to communicate findings, we still must summarize our data somehow. The choice of data visualization goes a long way in determining the degree of success in providing both a simple, interpretable summary, as well as a larger context. The app described in this blog is my attempt to demonstrate how an interactive geospatial data visualization can serve this mission.
The screenshot below is from an interactive data visualization of the 1991-2011 Indian Census data depicting “Households Classified by Source and Location of Drinking Water and Availability of Electricity and Latrine”.
Check out the visualization here.
This blog is divided into two sections. The first section discusses the rationale for selecting the data set and different ways to explore the visualization. The second section explores the mechanics behind creating the visualization in R for those who may be interested in working on similar projects. For a brief overview, you can also scroll through the slides below.
Why This Data Set?
Having invested some time in learning the sf package for working with geospatial data, I was keen to take up a geospatial data visualization project that would expand my skills with the sf, leaflet and shiny packages.
After browsing tables available in the Census Digital Library, I settled on this data set for a few key reasons. The first is that it illustrates the intersection of three important socioeconomic development indicators: access to electricity, latrines and water.
Admittedly, however, this data set is not the most up-to-date (the most recent Census was 2011). Undoubtedly, we can find more recent estimates of electrification or latrine access. Satellite images, for example, can even show electrification in real time. Nevertheless, the sheer richness of this data set attracted me.
This data set has the rare ability to provide spatial, temporal and social context for any of the metrics it tracks, such as electricity or latrine access. This means we can visualize the relationships between a metric like “Access to Electricity” and the geographic, demographic or social profile of an area.
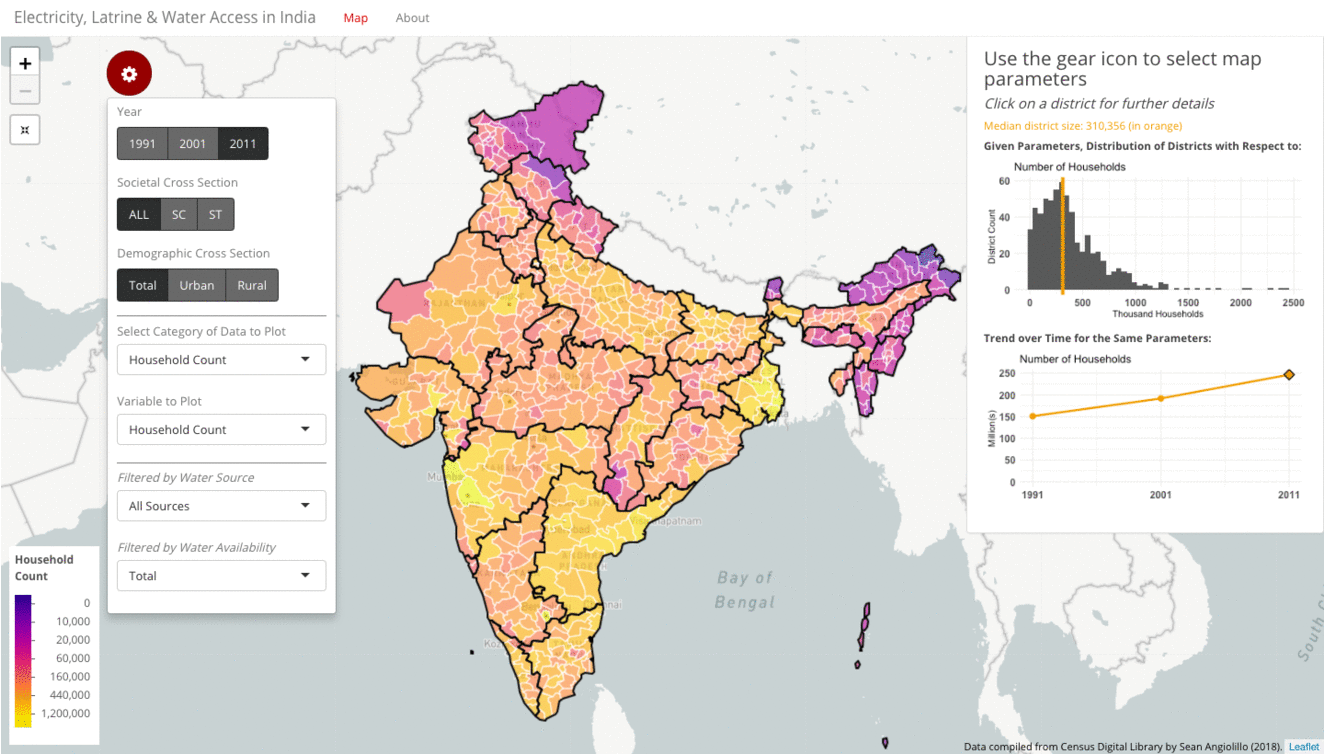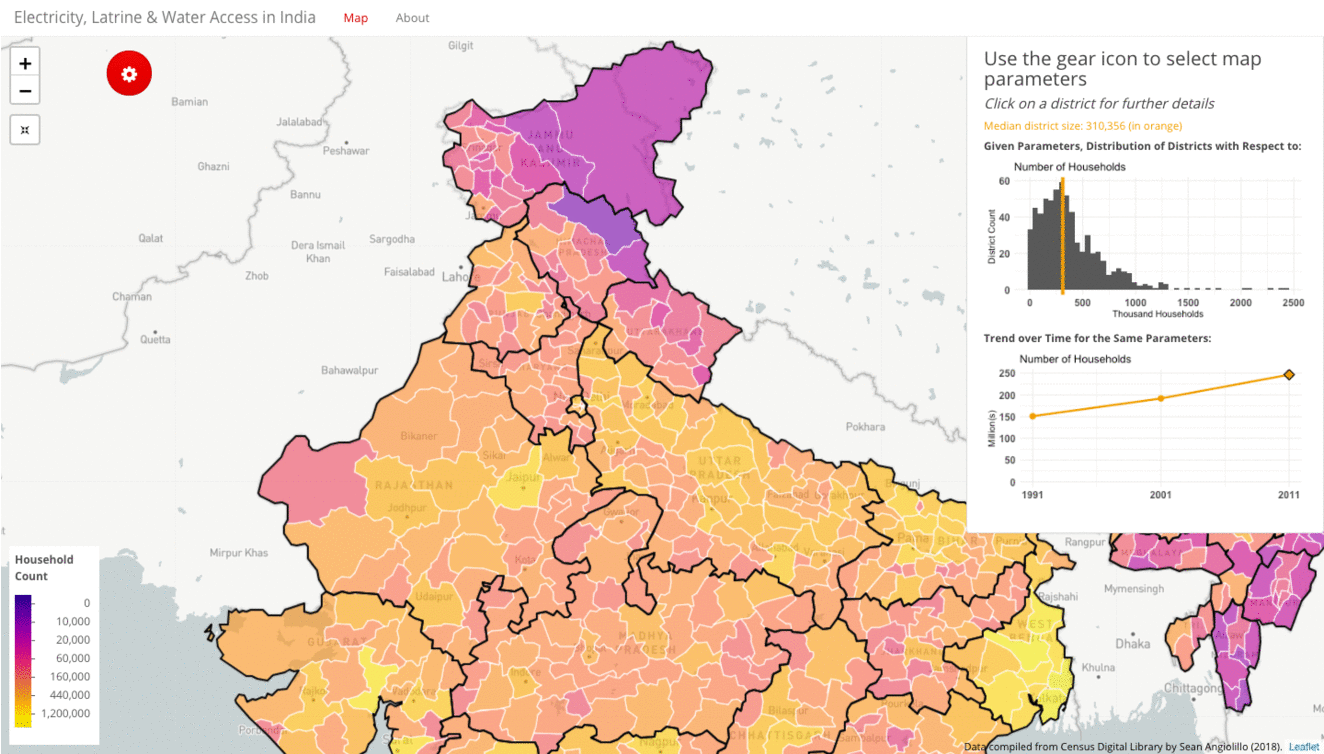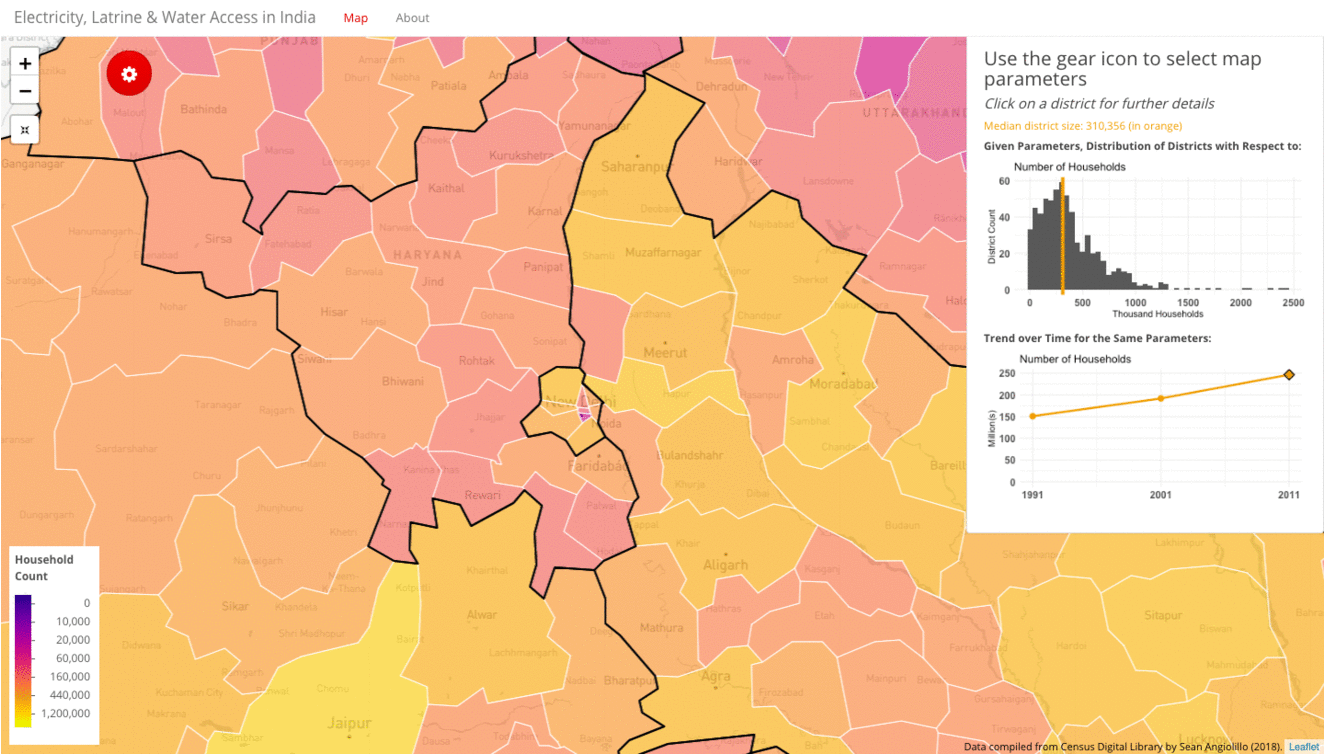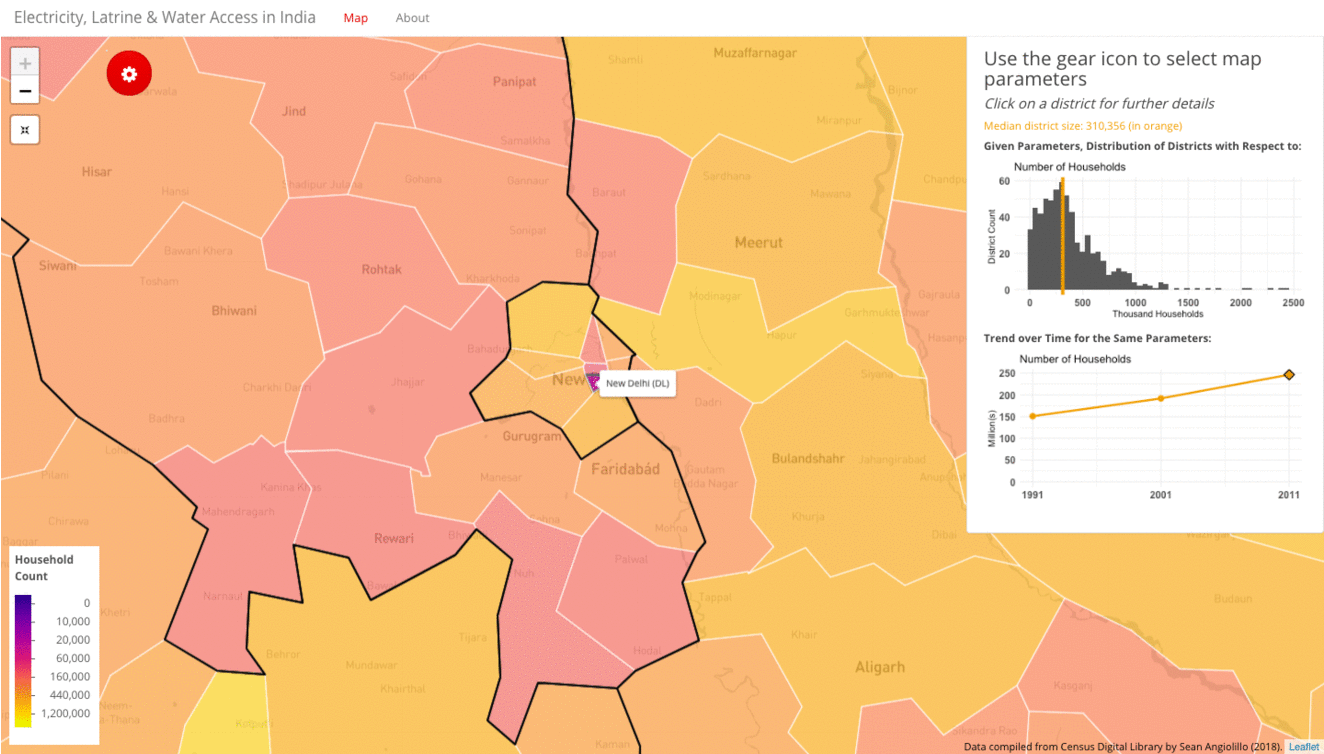
- By spatial context, I mean that the data set tracks its metrics at the all-India, state, district and even sub-district levels of administration. Using this data set, we can dive very deep into the geographic distribution. A one-number summary for any metric in India is rarely sufficient because metrics vary widely across geographies. Being able to plot this distribution across a map with a choropleth, as well as with a histogram, illustrates the geographic inequality inherent in development indicators in India.
- By temporal context, I mean that we have three decades of measurements tracking the same metrics, thereby illustrating the pace of progress over time. For example, for any given year, it is no surprise that districts in South India tend to have higher electrification rates than many of those in North India. However, having three census measurements allows us to visualize the rate of progress of any given district compared to its former self.
- By social context, I mean the data set can be cross-tabulated in interesting ways. For any particular year, we can compare urban to rural households across geographic spaces. We can compare the entire population to specifically SC or ST households in the same way. Even further than these traditional boxes, the data set also allows more narrow filtering by water source and water availability. With an astonishing level of detail, we can probe very detailed relationships– if we wished, for instance, mapping only rural ST households with a hand pump within premises as their source of water. While a choropleth does conceal the number of households in a particular category that might make such a query too narrow, we can at least begin to visualize some of these relationships.
Finally, while I have seen figures such as line plots tracking improvements in access to electricity or latrines, I have not seen the same data with water source or water availability. It is somewhat difficult to see the trend over time with regards to water sources because the levels fluctuate census to census. The data for water availability though is quite interesting to examine.
Exploring the App
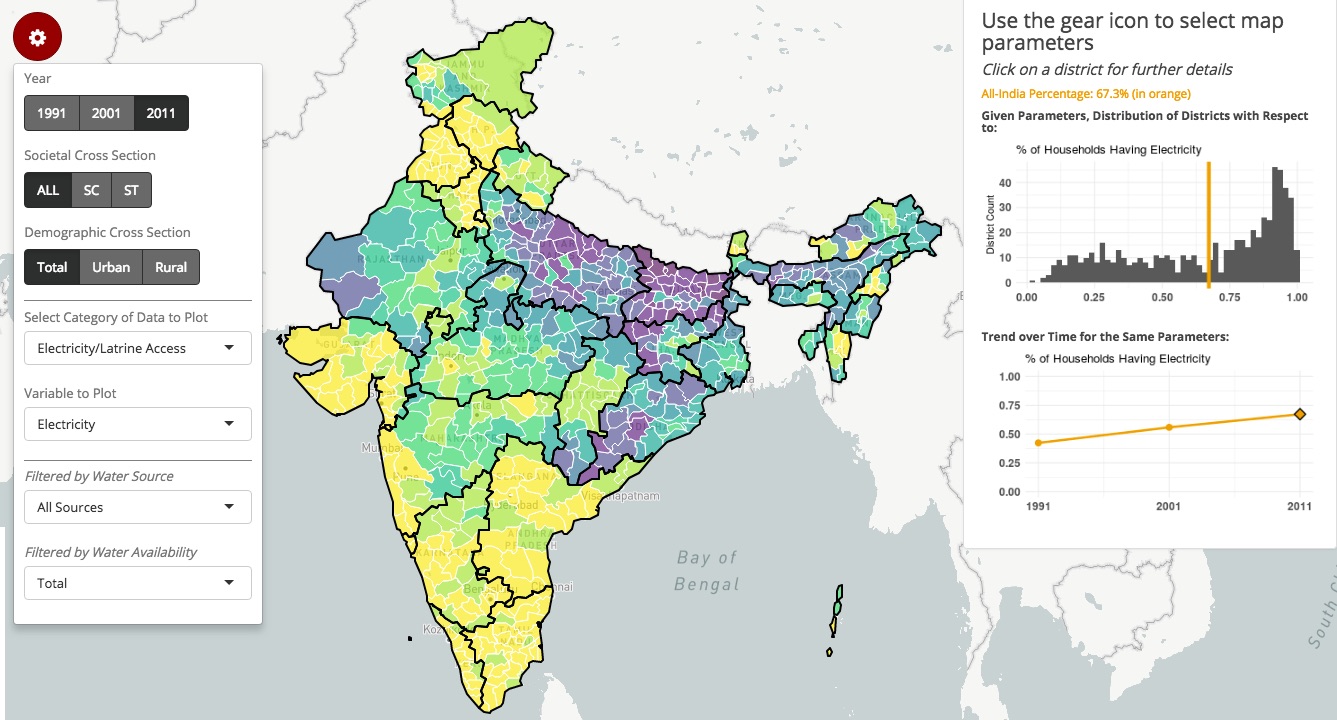
Given that the visualization is quite rich with information, let’s first start with a few different examples of how to interact with the visualization and explore the data, before delving into the details behind the creation of the app.
Track a Metric Across Years
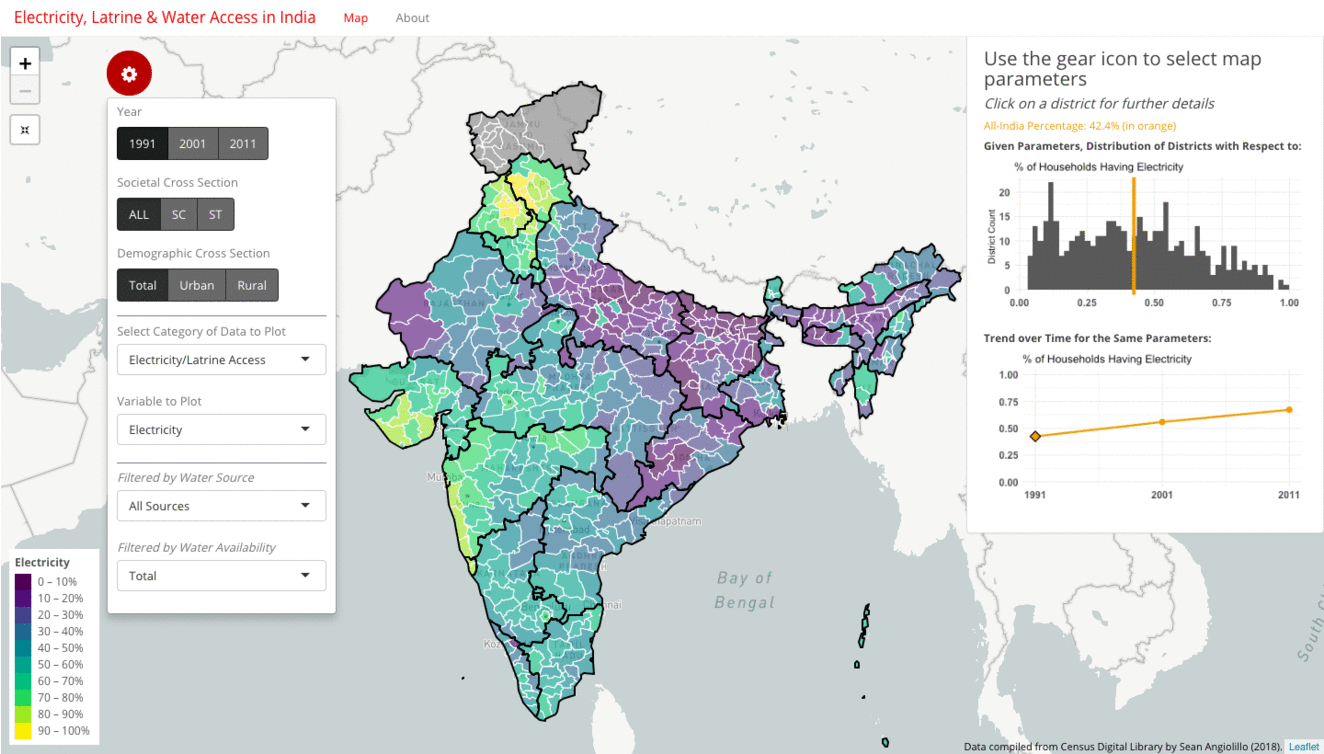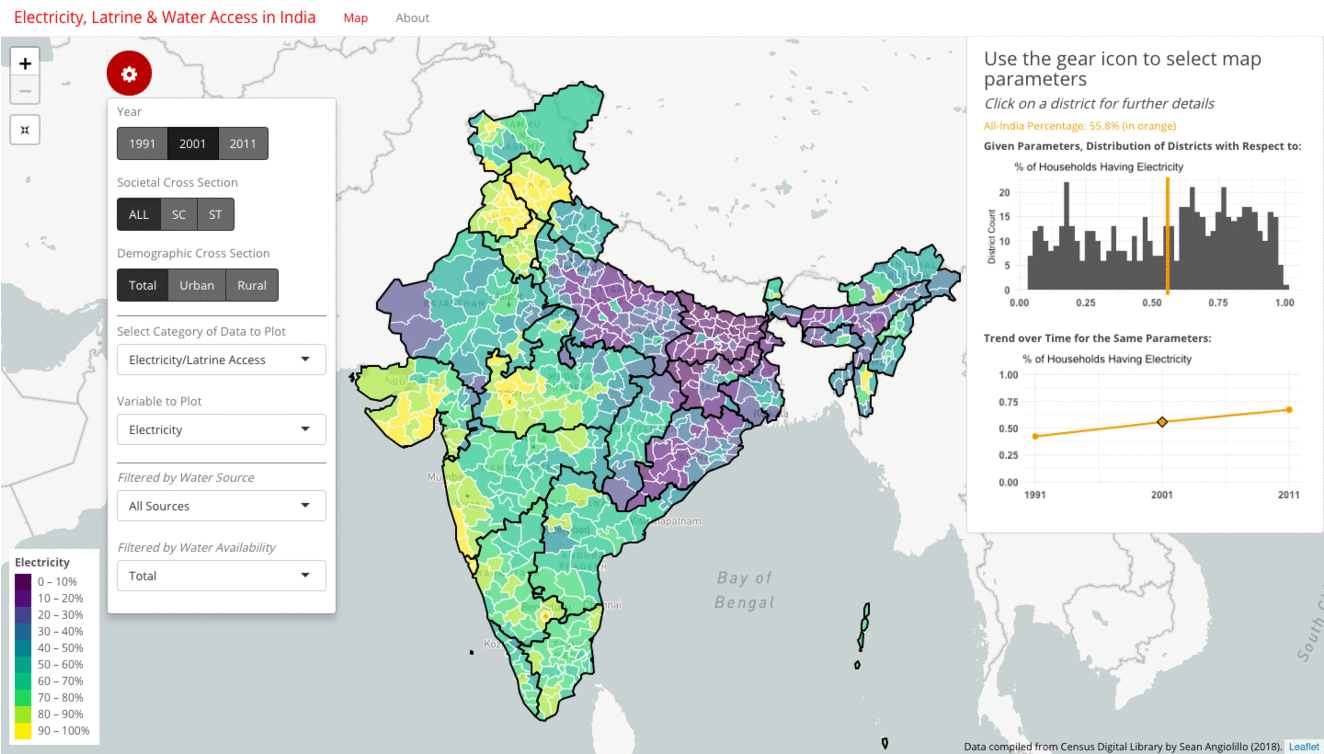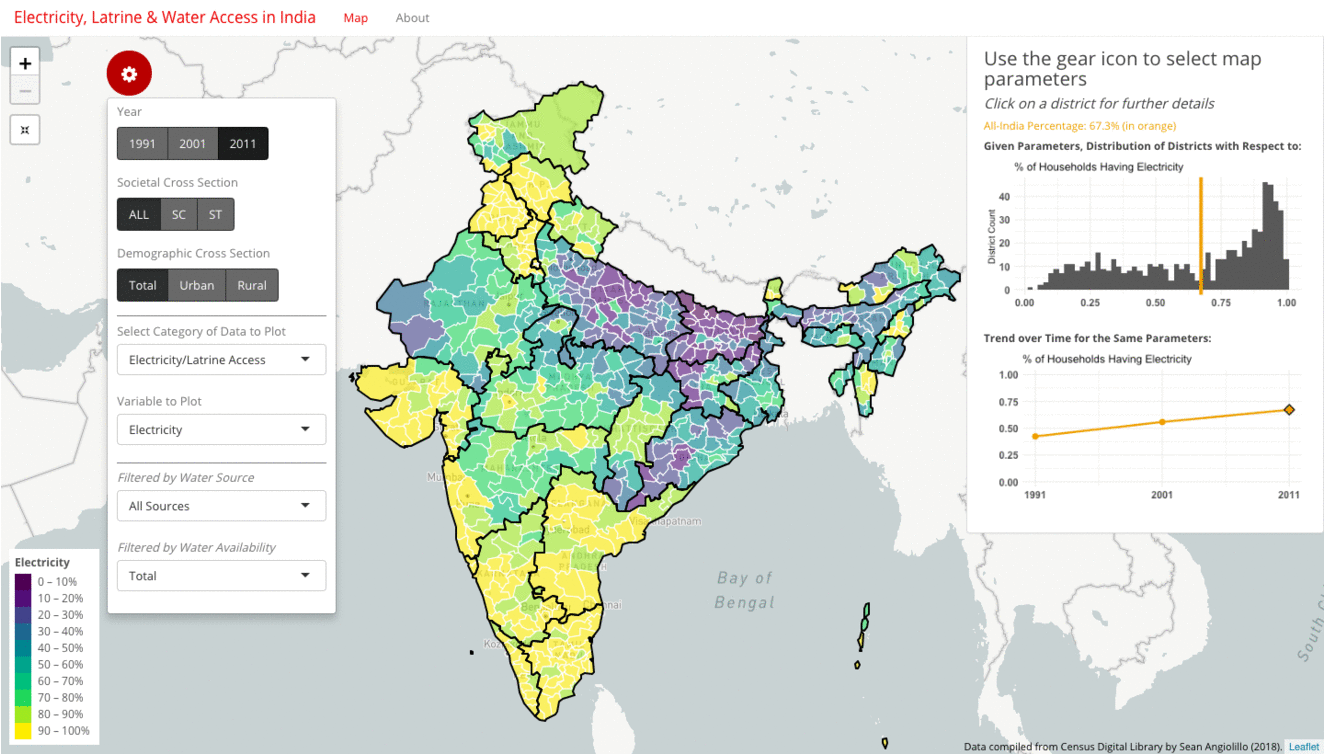
The first approach is to examine the progress of any particular metric over time. The gif below shows how the rate of household access to electricity has grown from 42% in 1991, to 56% in 2001, to 67% in 2011. These all-India figures are plotted in orange as intercepts on the histogram, as well as on the line plot. The map and the histogram work in tandem to reveal the distribution behind this single number summary.
While the average increases with each decade, the histogram also tracks how the distribution moves from slightly right-skewed in 1991 to strongly left-skewed by 2011. The map meanwhile provides a geographic indication of the extent of progress. Broadly speaking, Gujarat and the South Indian districts tend to move from the green bands of 40-60% to the yellow bands of 80-100%, while North and East Indian districts, such as those in Uttar Pradesh, Bihar, Jharkhand, Odisha, continue to remain in the purple bands of 0-30%.
Track a District Across Years
For any particular metric, the visualization allows deeper dives into any particular district. Clicking on a district triggers three additions:
- A table of raw district data
- Intercepts on the histogram for the district and the associated state data points
- The district point and state trend on the line plot. (Because districts change so frequently, it is more feasible to add the state trend to the line plot instead of the district trend.)
As shown in the gif below, household access to latrines in Jaisalmer, Rajasthan is one example of how we may explore trends from the perspective of a single district. In 1991, access to latrines across India was fairly uncommon at only 23% in a highly right-skewed distribution. Represented by the green intercept on the histogram and the green star on the line plot, Jaisalmer fell beneath not only the all-India average in orange, but also the Rajasthan state average in blue. As time progresses, we see the distribution of districts shifting right on the histogram and the map becoming more green and yellow. Jaisalmer, however, fails to keep pace. It is particularly clear on the histogram that the gap between Jaisalmer and the rest of India seems to be widening.

Compare Urban vs. Rural Households
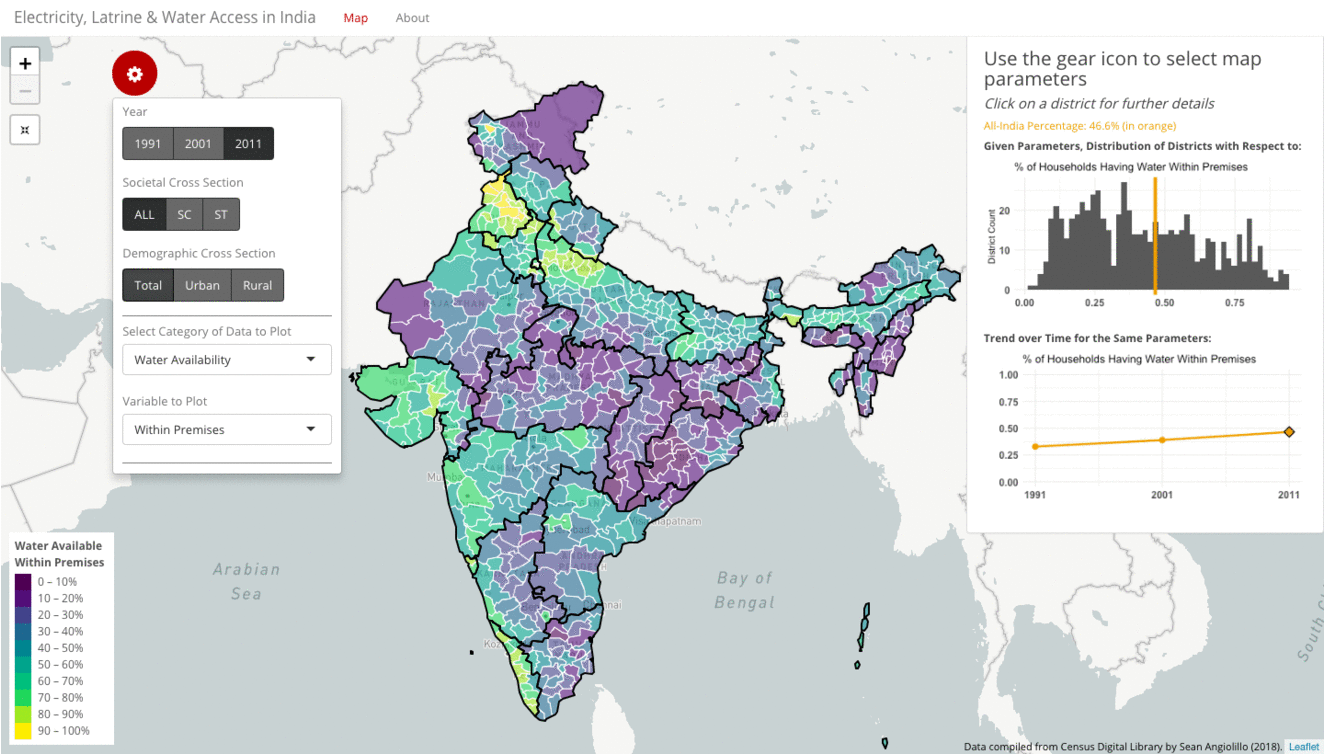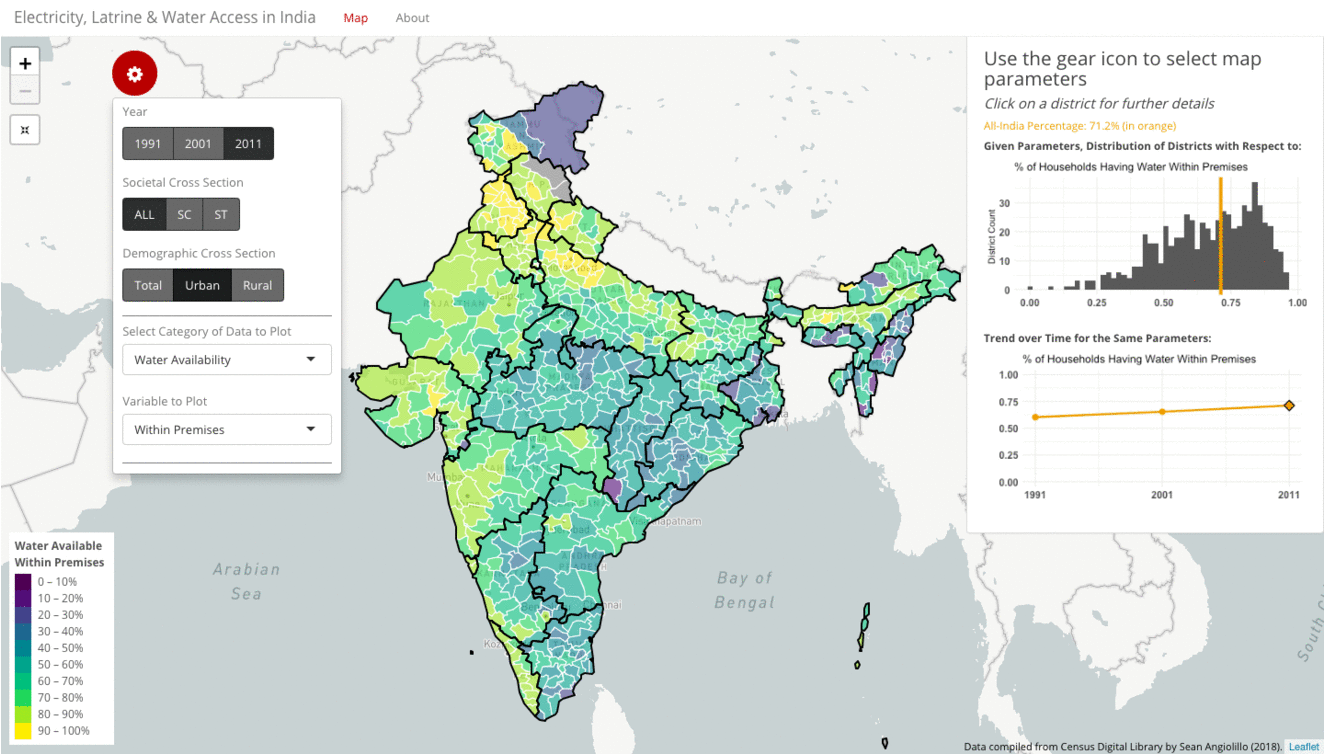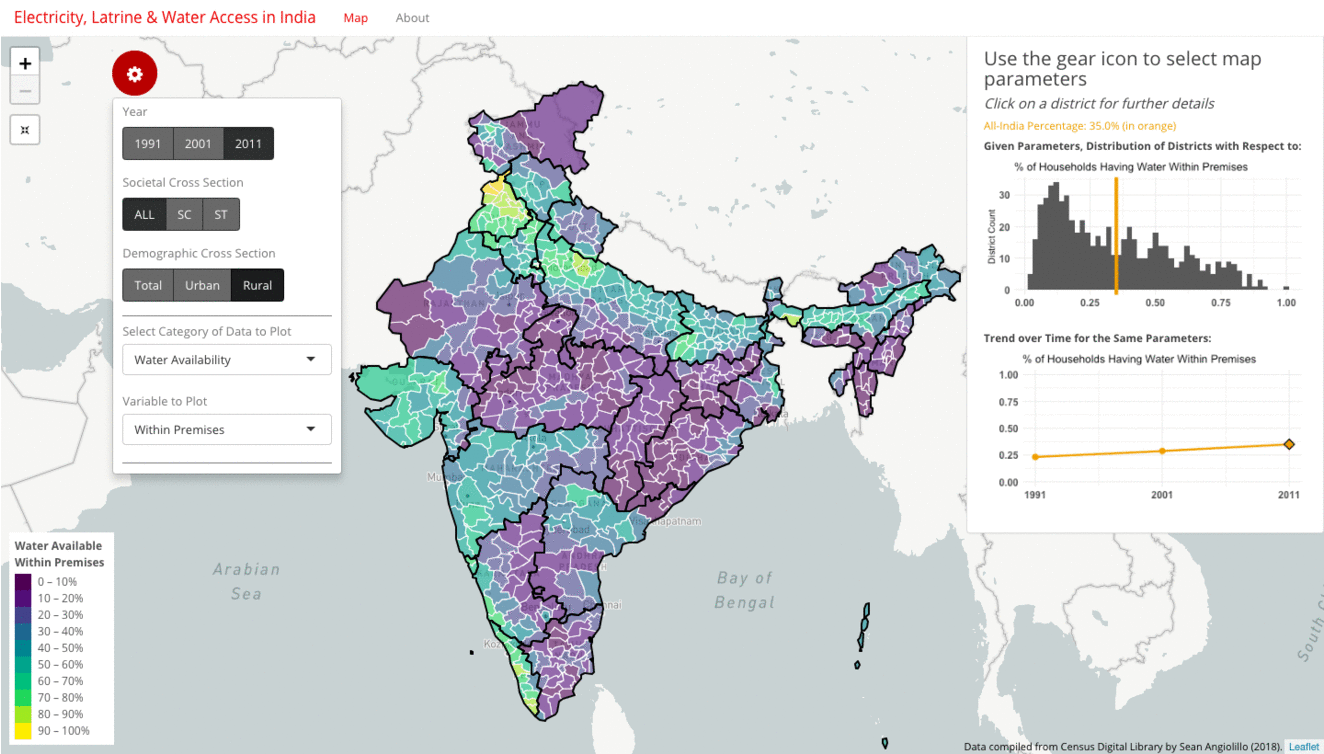
For many metrics presented in the visualization, the starkest contrast often lies between urban and rural households. The gif below highlights water availability within a household’s premises amongst all, urban, and rural households in 2011.
When examining all households, the picture is muddled. At an all-India average of 47%, there is no clear direction of skew in the histogram. Instead, the distribution is widely dispersed across the spectrum. Likewise, the map shows a broad mix of green and purple. When filtering to urban households, however, the picture changes dramatically. Now, at an all-India average of 71%, the histogram is left-skewed, and the map is mostly yellow and green. As you might guess, filtering to rural households has the opposite effect. The all-India average drops to just 35%. The histogram is now right-skewed, and the map becomes more purple.
Compare SC and ST Performance vs. the Total Population
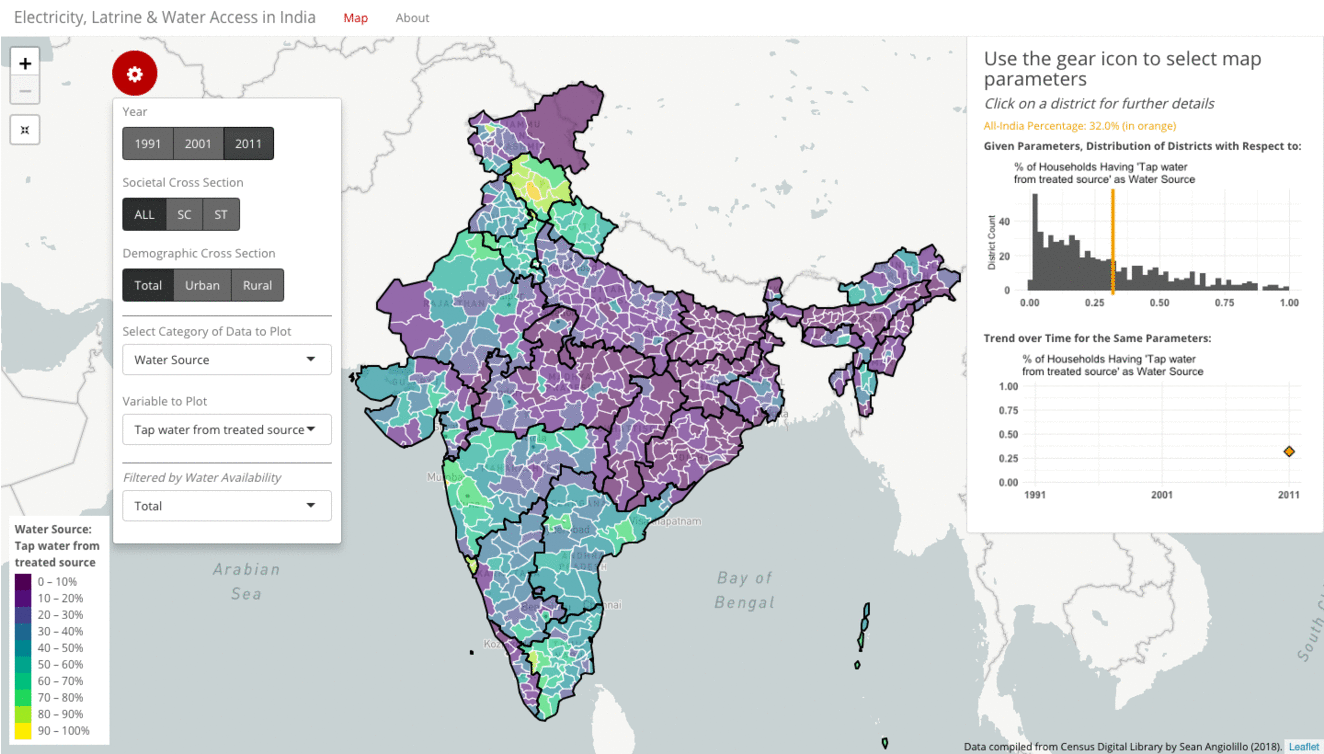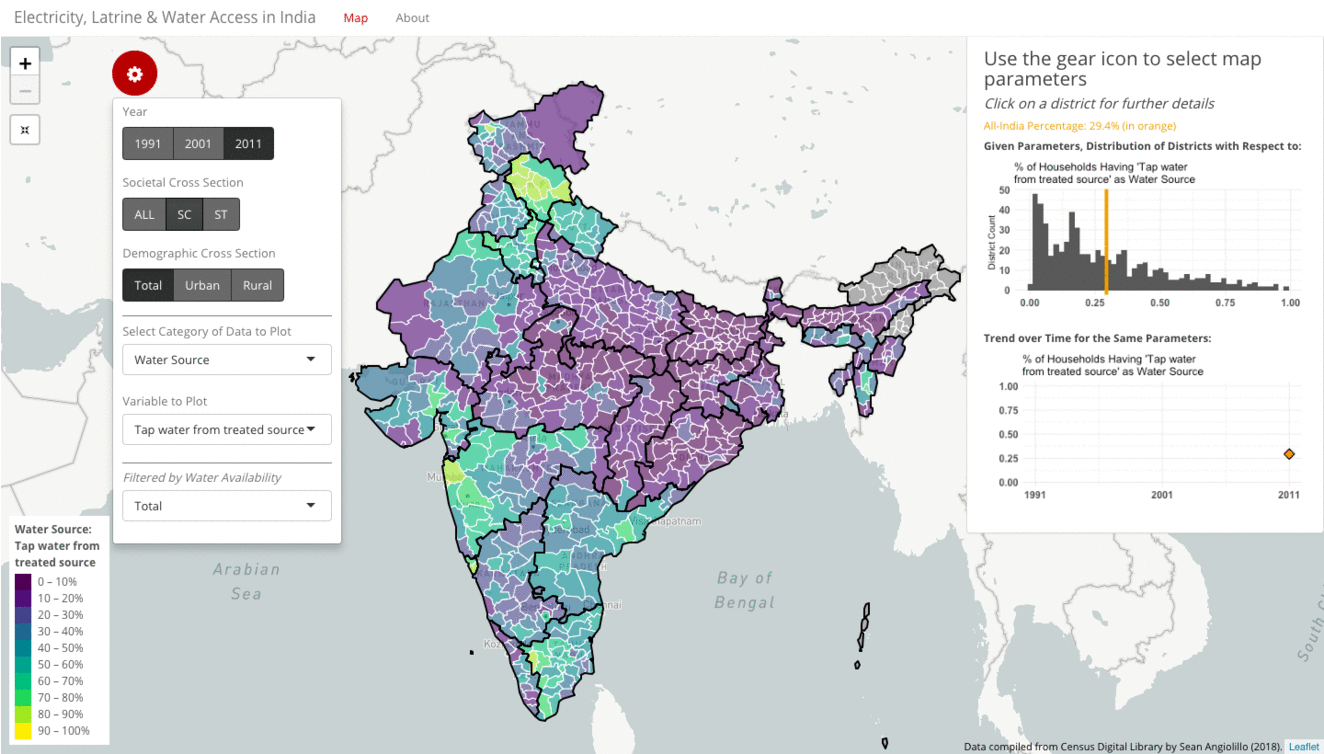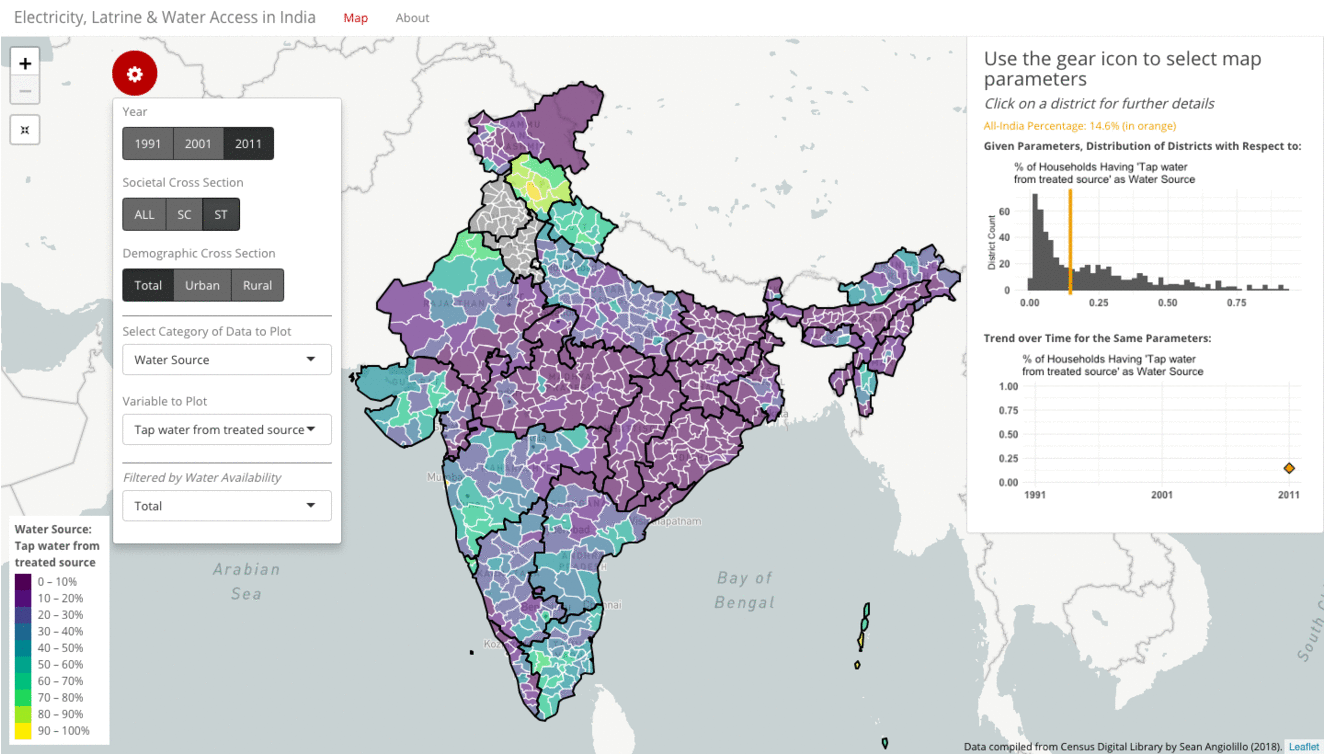
Instead of toggling the demographic cross-section filter, we can similarly toggle the societal cross-section filter to compare how a subset of SC or ST households fare against the total population. The gif below tracks the variable “Tap water from a treated source” as the household source of water in 2011. Only close to one-third of all households in 2011 have tap water from a treated source as their source of water. The distribution is highly right-skewed. The map is mostly purple across North and Central India, with more green in the South.
In this case, toggling to SC households does not produce a dramatically different picture. The all-India average drops slightly to 29%. The colors of the map look broadly similar. You can notice that much of the Northeast turns gray because those districts do not report having any Scheduled Castes.
Toggling to ST households has a slightly larger impact. Now the all-India average drops to only 15%. The histogram has the sharpest right skew of any option. The map looks broadly similar, but now Punjab and Haryana have turned gray.
You can also see that the line plot only depicts a single entry. The options for water source vary each census year, and so 2011 is the first year where “Tap water from a treated source” (as opposed to an untreated source) was an option. (Previously it was recorded only as tap water.) This variation makes trend analysis more difficult. While navigating across years, however, the visualization will default to the closest option if the same one is not available.
Explore Household Count Density
As discussed in greater detail later in this blog, one inherent weakness of a choropleth is that it conceals population density (as opposed to a dot density map). Colors are mapped to a geographic unit, the area of which is not uniform. This is a problem for Indian districts, which vary widely in both area and population. To mitigate this problem, the visualization provides household count plotted on a logarithmic scale.
In the wide view, the gif below shows low population density areas like the Northeast, Himachal Pradesh and Ladakh. The brighter yellow districts represent higher household counts. At this wide level, many of the densely-populated metro areas are hardly visible. For example, zooming in on Delhi reveals it is actually sub-divided into nine tiny districts. At a closer view, we can see a sparsely-populated New Delhi district in purple that otherwise would not have been visible.
When examining other data types through the choropleth and the histogram, it is important to be aware of the variety in area and population contained within each district.
Building the Visualization
Now that I’ve shown how to explore the data, let’s talk about the mechanics of how the visualization was constructed in R.
Getting Started with Shiny
Shiny is an R package that lets you develop interactive web applications directly in R, without needing to know languages like HTML, CSS and Javascript.
Read More: As an R Studio enterprise, Shiny has excellent documentation filled with webinars, tutorials, blogs, toy examples, and a gallery of more sophisticated apps.
A Shiny app can be as simple as a single app.R file. In more sophisticated cases though, it is more practical to separate the app into two files: ui.R and server.R. ui.R controls the app’s appearance, while server.R contains the logic that transforms a list of user inputs, such as dropdown menus or radio buttons, into various kinds of outputs, like plots or tables.
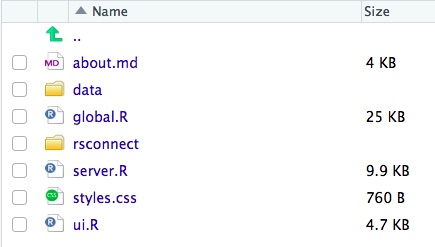
Beyond these minimum two files, larger projects often involve a few other important components. One is a separate data folder that holds all of the data read into the app. Another is a file, perhaps named global.R, that reads in data files, sets global variables, and contains functions to be used in server.R.
Particularly as complexity increases, it is an advantage to pare down the server.R file to only the reactive logic of Shiny. Setting variables, reading in data, and functions describing how to build objects can all be handled in a global.R file. Removing these elements allows you to better focus on the reactivity in server.R.
Lastly, you might add a styles.css file for custom styling. I chose to add includeCSS(styles.css) inside the header tag within my ui.R file. This allowed me to override any of the app’s default styling in a separate file without distracting from the structure of ui.R.
My project directory for this app shows just a few files: ui.R, server.R, global.R, styles.css, and a data folder.
Data Wrangling
The raw data for this visualization comes from the Government of India’s Census Digital Library.
Read More: Directions for finding the exact tables, and highlights on what data is missing can be found in the app’s “About” tab.
Wrangling the data into the correct format was a bit of an arduous process. Aside from individually downloading a few hundred Excel and CSV files, the first challenge was that each year is formatted differently. In fact, 1991’s data is structured in a significantly different format than that for 2001 and 2011.
Although I started out with the hope of writing functions for the cleaning process of a single year that would be able to process the other two, it was a much more manual effort. Copying and pasting code across years, and then making slight changes, did make my scripts less readable, but ultimately saved time as opposed to writing functions to handle all years.
A few key points I learned the hard way:
- Indian district names are not unique identifiers. Districts need to be coupled with their associated state for uniqueness. If only I had found this blog sooner for this tip.
- If programmatically reading in Excel sheets, be careful if there are multiple sheets. In one case, Andhra Pradesh decided to break their data into two separate sheets within the same Excel file, and so tracking down that missing data was exasperating.
- Implicitly missing data tripped me up initially. For example, there are no scheduled tribes in Punjab. There are no scheduled castes in parts of the Northeast. Figures for these categories are not reported as 0 or NA or NULL. They are just absent. Consequently, rather than such districts appearing gray or some color to distinguish their absence, the entire polygon would be missing. The
complete()function from thetidyrpackage was a lifesaver for this problem. - Another problem I faced was needing to join my census data with district shapefiles. The district names in my shapefiles rarely matched exactly with the census district names. These mismatches would occur in so many different ways that using regular expressions and string operations would be really tedious. For example, the 2011 Census Data has a district in West Bengal “South Twenty Four Paraganas”, but my shapefile is called “South 24 Parganas”; the Census has a district in Chhattisgarh called “Champa”, but my corresponding shapefile is “Jangjir-champa”.
After some Googling, I solved this shapefile problem with the levenshtein.distance() function from the vwr package. Essentially, it tries to “sound out” a piece of text and compares it to another piece of text in terms of “distance”. By ranking each census district name with all possible shapefile names in terms of their similarity, I was left with only a few districts to correct manually.
The Appearance
With the final data files in a new folder within my Shiny app’s directory, I could now pay attention to the app’s appearance, beginning with the ui.R file. The first step in designing a Shiny app is choosing an application layout. Among the simplest options is a sidebarLayout(), paired with a mainPanel(). I opted for a navbarPage(), which allows for a more full-screen view with tabs along the top, in my case, “Map” and “About”.
Within the navbarPage(), I created a page filled 100% with the leafletOutput(). The Leaflet map allows for full zooming and panning so it serves as an effective background tile, upon which layers can be added. The app’s plots are then drawn on top of the map in an absolutePanel().
In a few places, I needed the app’s UI to respond based on user input. For example, when “Electricity/Latrine Access” is selected, options for filtering by “Water Source” and “Water Availability” should both be present. However, if “Water Availability” is selected, then there can be no option to filter by “Water Source”.
Shiny provides four different approaches for creating a dynamic UI. I used both conditionalPanel() and renderUI() in different situations.
More Information: In addition to Shiny’s blog, Bárbara Borges Ribeiro’s talk on Dynamic Shiny Interfaces helps explain the use cases for the four different methods.
Although Leaflet’s addProviderTiles() function gives access to dozens of map tiles, I chose to design my own in Mapbox. My goal was to remove labels that did not concern India in order to remove distractions from the choropleth. I started with Mapbox’s light theme and removed layers like country and marine labels. In a bit of a hackish effort, I manually removed cities outside of India that appeared within view. When zooming in on the final map, landmarks still appear in neighboring countries, but at least from the original view, it was successful in removing markers outside of India. Setting the map’s maximum boundaries with Leaflet’s setMaxBounds() function also ensures the user does not stray too far from where the intended area of focus.
Read More: Check out this tutorial from Rick Majerus for creating your own custom map tiles in Mapbox.
The dropdown menu hidden within the gear icon comes from the shinyWidgets package, which extends the number of widgets Shiny offers by default. Being able to hide the menu yields more space to explore the map.
The app’s overall theme comes from the shinyThemes package. This package has more than a dozen themes ready to be added with one line. After adding a theme, I needed very little extra customization in the styles.css file.
One last UI touch was adding spinners to the plots with the shinycssloaders package. This package has a number of options to add waiting effects while outputs are loading by simply adding the withSpinner() function to outputs in ui.R.
Reactivity in Shiny
Reactive programming is the magic that makes Shiny apps interactive. It is also the most difficult concept within Shiny to grasp.
Read More: For those completely new to Shiny, I would recommend starting with Part 2 of the main Shiny webinar and later move on to the conference on Effective Reactive Programming when you have a handle on the basics.
The documentation above will do a much better job of explaining reactivity, but here is the key point presented in the Effective Reactive Programming conference: reactive() is for calculating values, without side effects; observe() is for performing actions, with side effects.
Although I have tried to follow this principle, undoubtedly reactivity in my own app could be more efficient. The screenshot below of my reactive log, however, demonstrates how complicated dependencies between objects in a Shiny app can become.

In my case, the main reactivity challenge stems from the fact that the “Water Source” and “Water Availability” levels differ for each year. For example, the 2011 data has eight different water sources compared to six in 2001. On top of that, I needed the app to automatically select the most logical option when changing years. For instance, if the user is filtering 2011 data by “Tap water from treated source”, and moving to 2001, the app should now filter by “Tap” instead of defaulting to any random choice. Ensuring the app changes its filters to the most sensible option across years hopefully makes the app more intuitive as the user adjusts parameters.
Working with Leaflet in Shiny
One last piece of this app’s foundation that deserves attention is working with Leaflet in Shiny. RStudio’s Leaflet documentation includes a section on using Leaflet with Shiny. Two points deserve highlighting:
- Draw only the underlying base map with
leaflet()and update it withleafletProxy()as necessary. While adjusting app parameters, you should notice that the base map does not redraw each time. Only the choropleth colors redraw themselves. Even the state borders redraw only when year changes, but not from any other parameter changes. To obtain a much snappier feel, useleafletProxy(), triggered by an observer, to update only what is necessary. - Take advantage of possible events in Leaflet. Using the pattern
input$MAPID_OBJCATEGORY_EVENTNAME, Shiny can store information from events such as clicks, mouseovers and mouseouts, which you can then manipulate. In my case, I was able to capture the event of clicking on a district shape, and use that information to display a table and add intercepts to the plots.
Read More: For more information on working with Leaflet, including Leaflet in Shiny, Abhinav Agrawal has an excellent YouTube series, accompanied by scripts in Github.
Working with Geospatial Data in Shiny
I also want to add two small points on working with geospatial data in Shiny.
Depending on your objectives, shapefiles may be more complex (and therefore larger in size) than what is actually necessary. In my case, I have used the ms_simplify() function from the rmapshaper package to keep only 1% of the points in my original district polygons. When zooming in closely on the map, it becomes obvious that the district shapes are quite rough; but at an all-India view, the district lines, with just 1% of their original points, give an accurate representation.
One last point is to only use sf objects where they are absolutely necessary. For data manipulation, it is great that sf objects are also dataframes, but explicitly dropping the sf geometry where it is not required saves processing time. In my case, I only need the sf object to redraw the map colors. In all other places, the histogram and the line plot for instance, working with only the respective dataframe of the same parameters as the sf object noticeably improved the app’s responsiveness.
Choice of Analysis Unit
Although the Census tables used for this visualization came at the all-India, state, district, and even sub-district levels, I chose to use the district level as the primary unit of analysis. This decision has important consequences for the visualization.
Despite wrangling the sub-district-level data, my inability to find the corresponding shapefiles ruled out any possibility of using them in a choropleth. The sub-district level also might be a bit too fine-grained without very specific motivating questions. The state-level data, on the other hand, somewhat precludes the need for a choropleth at all. Thirty-five entries in a bar plot is busy, but probably manageable if you are familiar with India’s basic geography.
At the district level, however, with a range of 466 to 640 units, a choropleth becomes advantageous. A bar plot with hundreds of districts is untenable, but the choropleth is able to depict the geographic distribution of any given parameter across all of India in one image.
Choosing a choropleth at the district level, however, comes with negative consequences as well. These consequences stem from the fact that districts in India are hardly uniform in area or population. To cite one extreme example, in 2011, the district of Bangalore in Karnataka had nearly 2.38 million households, while Leh in the state of Jammu & Kashmir held less than 21,000 households. Nevertheless, on the choropleth, Leh takes up a very large area at India’s northernmost tip, while Bangalore, as a densely-populated metro, is hardly visible. This problem similarly plagues the histogram. Both districts, despite very different household counts, contribute equally to the histogram as one district.
I have tried to mitigate this discrepancy in two ways:
- The histogram plots the corresponding all-India figure as an x-intercept. Note that this orange line is not a median of district values, but the actual all-India data point reflecting the appropriate total household count of India. In many cases, this intercept looks like a median, suggesting that the histogram is in fact not a bad representation of the data’s distribution.
- Clicking on a district provides the raw figures behind the choropleth, allowing you to see the total number of households in the district.
- Finally, household count is available as a separate variable to plot, which, now on a logarithmic scale, depicts the geographic distribution of India’s population density. When mapping household count, the histogram plots the median district size, showing its right-skewed tail.
Scales and Color
Unlike the electricity, latrine and water data, I used a logarithmic scale to plot household count. Changing from the default viridis scale to its plasma variant is intended to alert the user to an important difference between these data types.
Electricity, latrine and water data are all percentages ranging from 0 to 100. For this data, I equally divided the scale into ten colors. The fixed nature of these color bins hopefully builds a level of familiar expectation for the user, regardless of what data is being mapped. Whether plotting electricity, latrine, or water availability, bright yellow means above 90% and dark purple means less than 10% for that given parameter.
In many cases, the data does vary quite widely, with some data close to 0 and others close to 100. In other cases though, particularly as you filter into more narrow categories, the user might find a map with very little variation. Although a flexible scale would allow the colors to attach themselves to smaller increments of change, the fixed deciles, I think, is the much better option because it helps enshrine the meaning of color for the user to a particular value.
Household count data, however, is not bound between 0 and 100. It is heavily right-skewed and hence requires a different approach. Without a logarithmic scale, the choropleth would be mostly one color with a few very high-density districts standing apart. A logarithmic scale, while more difficult to interpret, reveals much greater differentiation between districts of varying sizes.
One additional challenge of using the logarithmic scale is that as a user filters the data, the range of data changes considerably. While percentages always range from 0 to 100, household count may range from a few thousand to a few million if looking at total figures, but may have a much smaller maximum value if looking only at a smaller subset of data, such as rural ST households. Accordingly, the axes on the histogram and line plot must be allowed to float. One useful trick I learned was that it is not necessary to set an upper bound in ggplot2‘s scale_*_continuous() function. You can set the limits argument as c(0, NA), and it will choose the upper limit based on the data at hand.
Viridis was an obvious choice as the choropleth color scale. Originally developed for the Python package matplotlib, this color scale has been implemented in R and is even now directly available in ggplot2 in the function scale_color_viridis_c(). This color scale has the advantage of being perceptually-uniform and perceived by the most common forms of color blindness.
Taking a recommendation from Claus Wilke’s chapter on color pitfalls in data visualization, to distinguish between the all-India, state and district points, I used the Okabe and Ito color scale, which is a colorblind-friendly scale for discrete colors.
Read More: To learn more about geospatial data visualization, see chapters of two recently released open access books on data visualization: the “Visualizing geospatial data” chapter from Fundamentals of Data Visualization by Claus O. Wilke and the “Draw Maps” chapter from Data Visualization: A Practical Introduction by Kieran Healy.
Trend Continuity
The goal of the line plot is to present a picture of progress over time. Using the same orange color is intended to communicate that this is the all-India trend. I have then used a different point shape to indicate the current year. As you filter to more narrow categories, you may notice the line breaking or not being present for certain years. This may be because a certain level (such as water source or water availability) is missing for a particular year.
As mentioned earlier, when a district is clicked, three actions occur in the side panel.
- A table appears giving the exact figures for the district.
- The district and associated state figures are added to the histogram as x-intercepts.
- The state trend line is added, along with the district point for that year.
I ultimately decided it was unfeasible to add a district trend line because districts change so frequently. With each new census, districts are frequently divided and redrawn, making the continuity of a district over time much harder to grasp. Even if a district retains its name across all years, its borders have very likely changed.
Instead, I have compromised by adding the district data point to the line plot for the selected year and the trend line for the respective state. State boundaries do, of course, change as well. States like Chhattisgarh, Jharkhand and Uttarakhand did not exist in 1991. Accordingly, for example, the Bihar trend line includes the territory now known as Jharkhand in the 1991 total, but I think this is a small sacrifice.
Final Thoughts
I hope this blog has helped demonstrate how, with the help of R packages like shiny, leaflet, and sf, it is relatively easy to build appealing interactive applications for exploring geospatial data. For those interested in even finer details of the visualization, the R scripts are available on Github. My other data projects can be found at my website. Feedback is most welcome!
Photo by Patrick Beznoska on Unsplash



1 Comment
Hi
This is Gulshan Kumar Ph.D. student working on Public health facility. Recently I am learning R and I come across socialcops website and there I found your work. You have done a great job as. I really appreciate your work and lecture as very interesting. I will be happy to learn these techniques. I started mapping in GIS software but recently I come across R software and I found that it is a very easy and powerful tool in creating and replicating maps. I would like to thank you for sharing your work with us.