
At the 14 July R User Meetup, hosted at Atlan, I had the pleasure of briefly introducing the relatively new tidytext package, written by Julia Silge (@juliasilge) and David Robinson (@drob).
Essentially this package serves to bring text data into the “tidyverse”. It provides simple tools to manipulate unstructured text data in such a way that it can be analyzed with tools like dplyr and ggplot2.
If you are already familiar with these tools, then the package is very helpful. Instead of learning a whole new set of tools to specifically analyze text data, with this package, you can bring text data into your normal data analysis pipeline. This is really important because there are many sources of unstructured text data that we can now begin to derive value from using the tools we already know.
Getting Started
The tidytext package can be easily installed from CRAN. Although I only use dplyr in this blog, I have also loaded the tidyverse package to emphasize that tidytext works with all tidy tools.
As a demonstration, I have scraped together a corpus of English translations of the Prime Minister’s “Mann Ki Baat” radio addresses using Hadley Wickham’s rvest (think “harvest”) package.
In the simplest form, you can imagine a dataframe with two columns. One column is the collection of text documents. In this case, it holds radio addresses, but you could imagine it holding anything from books, customer reviews, tweets, etc. The other column has to be some kind of identifying trait. In this case, it is the date of the speech, but it could be authors or places, depending on the example. We could have more identifying columns (for instance, publisher and author if we had books), but we only need one for this example.
What is important to note here though is how the data is structured. We have (often very long) character strings where each speech is one row. The question is now how we manipulate this structure in order to derive value from it.
The Tidy Text Format
The tidytext package structures text data upon the principle of tidy data. As well documented in a chapter of Hadley Wickham’s R for Data Science, three rules make a data set tidy:
- Each variable must have its own column.
- Each observation must have its own row.
- Each value must have its own cell.
In their book, Silge and Robinson define the tidy text format as being a table with one-token-per-row. We use the unnest_tokens() function to transform our data set from one speech per row to one word per row.
In this example, I have chosen to define one token as one word, but there are many other options. For example, I could define one token as a bigram (two words). Although I have not personally explored them, you can also define tokens as characters, sentences, lines, etc. It entirely depends on your objectives. Now with each word as one row, you can probably already begin to see how you can use dplyr functions like count() and group_by() to start to analyze the corpus.
Note: The tidytext package relies on the tokenizers package for tokenization. Tokenization can be a computationally heavy operation, and so, at least out of the box, I have struggled using it for very large data sets. In this case, you may want to try the quanteda package which, as I understand it, makes better use of parallel processing by default. Still, the tidytext package seems the most natural place to start for any text mining project.
The Document-Term Matrix (DTM) Alternative
Before discussing further manipulations of the tidy text format, I want to briefly consider how other text mining packages structure text data. The tm package, for instance, is a popular text mining package in R that focuses on creating a Document-Term Matrix (DTM) or a Term-Document Matrix (TDM), depending on which are rows and which are columns.
Skipping over the manipulation steps to prepare the DTM, I want to draw attention to the difference in formats between the earlier tidy text dataframe and the sparse matrix above. Personally, if you are a fan of the tidyverse, you are most likely much more comfortable working with dataframes, at least as a starting point. Depending on your objectives, a matrix might be needed, but if you are exploring a new corpus, I would highly recommend beginning your investigation in the tidy text format. Moreover, the tidytext package contains functions to tidy DTMs and convert between different formats as needed. (See Chapter 5 of Text Mining with R.)
Corpus Pre-Processing
As with most data analysis projects, some amount of data cleaning is typically required. This is almost always the case with text data. After reading in a corpus, you will likely need to address questions such as:
- How should I treat numbers, special characters, punctuation, contractions, and abbreviations?
- Should I remove stop words (small words like a, an, is)?
- Should I treat upper and lowercase characters the same?
- Should I stem words (remove inflection endings)?
If you’re using tm package, you typically build your own clean_corpus() function, sequentially bundling together calls like tm_map(corpus, removePunctuation), tm_map(corpus, stripWhitespace), or tm_map(corpus, removeNumbers). You might find many of these specialized functions useful, but they require some extra effort to learn. With the tidytext package, on the other hand, we have the full suite of tidy tools at our disposal — for instance, stringr to help clean text data.
The tidytext package makes some preprocessing choices for us by default. For instance, it converts all upper case characters to lower case. In the example below, I have chosen to remove stop words. The tidytext package makes this step very easy because anti_join() is a dplyr function we already know, and stop_words is a dataframe bundled into the package that we can view and modify like any other dataframe. (For more information on different kinds of joins in R, please see the relational data chapter of R for Data Science.)
To remove stop words with the tm package, we could run a line like: tm_map(corpus, removeWords, c(stopwords("en"))). We can achieve the same objective, but we have to learn a new function to do so.
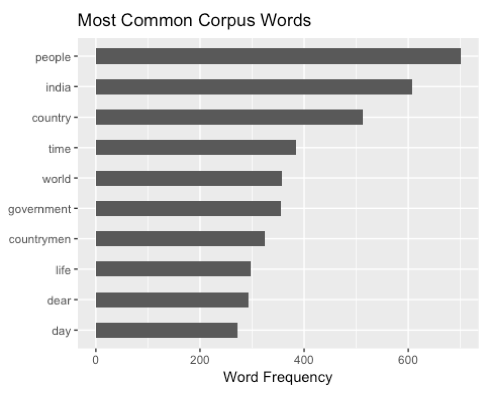
Calculating Word Frequencies
Once we have a corpus cleaned and ready for analysis, the first thing we might like to do is start counting. Counting of course is quite simple with dplyr.
If we have counts, we can easily pipe that dataframe into ggplot2.
Sentiment Analysis
We could also take our clean corpus and try some sentiment analysis on it. In this context, sentiment analysis relies on pre-defined lexicons that categorizes words according to sentiment. For example:
- the Bing lexicon labels positive and negative words
- the AFINN lexicon gives words a rating from -5 to 5
- the NRC lexicon categorizes words into more specific feelings like joy, fear and sadness
The get_sentiments() function allows us to load these lexicons as dataframes, which we can then bind into our corpus with functions like anti_join().
As our data has maintained a tidy structure, we can again pipe it into ggplot2.
Calculating TF-IDF
One last application I will demonstrate here is called term frequency–inverse document frequency (TF-IDF). I will not go into the statistics behind it, but the idea is to measure how important a word is to a document in a collection of documents.
For instance, if we simply count the most frequent words in a corpus, we will likely get words like “the”, “a”, and “is”. If we remove stop words, in our Mann Ki Baat example, we get words like “people”, “country”, and “India”. This is an improvement, but it’s still not too interesting.
The TF-IDF calculation looks at the term frequency, but weights it by how rarely a word is used. In our case, words like “people”, “country” and “India” may be very frequent, but because they are also very common (they are found in every radio address), they score poorly in terms of TF-IDF.
To calculate this measure with the tidy_text package, we only need the bind_tf_idf() function. Note that, in the pipeline below, only two functions unnest_tokens() and bind_tf_idf() are from the tidytext package, whereas everything else is simply dplyr.
Once again, we can continue the same pipeline into ggplot2 to visualize our results.

Going Further
This was only a brief introduction to what the tidytext package has to offer. For instance, topic modeling (that is, unsupervised classification) is also within the scope of the package. Hopefully, however, I have sold you on the merits of structuring text data in a tidy format.
For more information, I would highly recommend visiting www.tidytextmining.com. One of the key advantages of the tidytext package is its documentation. Rather than a single vignette, Silge and Robinson have written a freely available book, “Text Mining with R”, that not only gives a thorough introduction to the package’s functions, but also places the field of text mining in context.
DataCamp subscribers can also check out Julia’s course on sentiment analysis using the tidytext package. Lastly, to find a full treatment of the Mann Ki Baat example I used in the presentation, please see this shiny app, the full code for which is available on Github.
Header image credit: Raphael Schaller



1 Comment
Pingback: An Introduction to Tidy Text Mining – Atlan