
Introducing a new way of storing metadata for today’s limitless use cases like data discovery, lineage, observability and fabrics
Data is exploding.
Data teams are more diverse than ever — data engineers, analysts, analytics engineers, data scientists, product managers, business analysts, citizen data scientists, and more.
The data tools and infrastructure they use are… complicated. These include data warehouses, lakes, lake houses, databases, real-time data streams, BI tools, notebooks, modelling tools, and more.
All of this has led to chaos like never before.
“What does this column name mean?”
“Can I trust this data asset? Where does it come from?”
“Arrgh… where can I find the latest cleaned dataset for our customer master?”
These are the types of messages data teams now deal with every day.
In the past 5 years, as the modern data stack has matured and become mainstream, we’ve taken great leaps forward in data infrastructure. However, the modern data stack still has one key missing component: context. That’s where metadata comes in.
The promise of metadata
In this increasingly diverse data world, metadata holds the key to the elusive promised land — a single source of truth. There will always be countless tools and tech in a team’s data infrastructure. By effectively collecting metadata, a team can finally unify context about all their tools, processes, and data.
But what actually is metadata, you ask? Simply put, metadata is “data about data”.
Today, metadata is everywhere. Every component of the modern data stack and every user interaction on it generates metadata. Apart from traditional forms like technical metadata (e.g. schemas) and business metadata (e.g. taxonomy, glossary), our data systems now create entirely new forms of metadata.
- Cloud compute ecosystems and orchestration engines generate logs every second, called performance metadata.
- Users who interact with data assets and one another generate social metadata.
- Logs from BI tools, notebooks, and other applications, as well as from communication tools like Slack, generate usage metadata.
- Orchestration engines and raw code (e.g. SQL) used to create data assets generate provenance metadata.
Burgeoning metadata, burgeoning use cases
All these new forms of metadata are being created by living data systems, sometimes in real time. This has led to an explosion in the size and scale of metadata.
Metadata is itself becoming big data.
Not only is more metadata being generated and captured than ever before, but fundamental advances (i.e. elasticity) in compute engines like Snowflake and Redshift now make it possible to derive intelligence from metadata in a way that was unimaginable even a few years ago.
For example, query logs are just one kind of metadata available today. By parsing through the SQL code from query logs in Snowflake, it’s possible to automatically create column-level lineage, assign a popularity score to every data asset, and even deduce the potential owners and experts for each asset.
As metadata increases, and the intelligence we can derive from it increases, so does the number of use cases that metadata can power.
Today, even the most data-driven organizations have only scratched the surface of what is possible with metadata. But using metadata to its fullest potential can fundamentally change how our data systems operate.
For example, imagine a world where these situations are the norm:
- When a data quality issue is detected in a source table, the system automatically stops the downstream pipelines to ensure that incorrect data doesn’t make its way to the dashboard. Or better yet, the system uses past records about data quality failures to accurately predict what went wrong and fix it without any human intervention.
- The system leverages past usage logs to automatically tune data pipelines and optimize compute performance by shifting loads towards more-used data assets and optimizing the schedules of data pipeline runs.
In the past few months, concepts such as the Data Mesh, Data Fabric, and DataOps have been gaining more momentum, widely popularized in this article by Zhamak Dehghani. However, all of these concepts are fundamentally based on being able to collect, store, and analyze metadata.
Why do we need a metadata lake?
In 2005, “data” was in a similar position to the one metadata is in today. There was more data being collected than ever before, with more ways to use it than a single project or team could dream of.
The problem is that, in the world of big data, we don’t really know what value the data has… We might know some questions we want to answer, but not to the extent that it makes sense to close off the ability to answer questions that materialize later.
Dan Woods in Forbes, 2011
Data had limitless potential, but how can you set up a data system for limitless different use cases and users?
This is what led to the birth of a data lake. Instead of storing data in “some ‘optimal’ form for later”, a data lake is a single, massive repository to store all kinds of data — structured and unstructured data, and data in both its most raw and processed forms. This variety of flexible data could then be used to drive a variety of use cases from analytics to data science to machine learning.
I believe that we are at a similar juncture with metadata. Today, there is more metadata being collected than ever before, and it has more potential use cases and users than anyone can imagine.
This is where I believe there is the need for a metadata lake: a unified repository to store all kinds of metadata, in raw and further processed forms, which can be used to drive both the use cases we know of today and those of tomorrow.
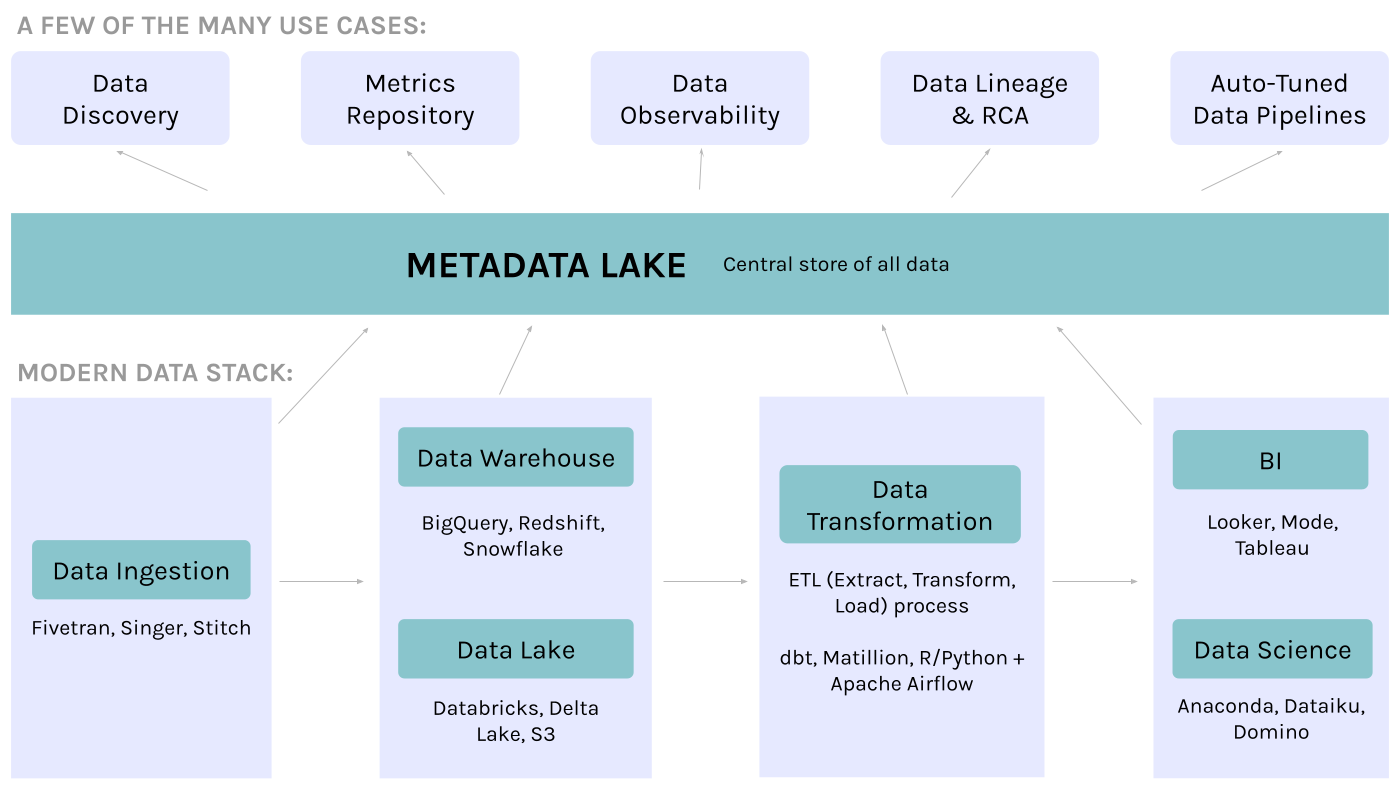
3 characteristics of a metadata lake
1. Open APIs and interfaces
The metadata lake needs to be easily accessible, not just as a data store but via open APIs. This makes it incredibly easy to draw on the “single source of truth” at every stage of the modern data stack.
For example, it should be incredibly easy to take metadata from the metadata lake and integrate it into the hover on a Looker dashboard. Or leverage lineage and provenance metadata to drive better data observability. Or take on any of the hundreds of use cases where metadata comes alive.
Like I mentioned in my article on 2021’s data trends, metadata is just coming of age. In the next few years, many data teams will start leveraging metadata, but they’ll likely start with a solution just for a single use case, such as data discovery, data observability, or lineage.
However, as they decide what metadata product or solution to adopt, it’s important that these customers think beyond that one use case. It’s important to consider a solution’s flexibility and architecture, and to check that the fundamental metastore is open and can be used for a wide variety of use cases and applications in the future.
2. Powered by a knowledge graph
Metadata’s true potential is unlocked when all the connections between data assets come alive. For example, if one column is tagged as ‘confidential’, this metadata can be used along with lineage relationships to tag all the other columns derived from that particular column as confidential.
The knowledge graph is the most effective way for these interconnections to be stored.
3. Power both humans and machines
The metadata lake can be used to empower both humans (such as discovering data and understanding its context) and machines or tools (such as auto-tuning data pipelines, as mentioned above). This flexibility is a reality that needs to be reflected in the fundamental architecture.
Looking forward
As we delve deeper into metadata, I think it’s clear that the metadata lake will become the cornerstone for the next wave of innovation in the data management space. It wouldn’t be surprising to see a new generation of metadata solutions enter the market in the next few years. After that, the metadata lake may even power entire categories of companies that will add a layer of data science and analytics on top of metadata.
Shout-out to my co-founder, Varun for first coining the term “Metadata Lake”.
This article was originally published in Towards Data Science.
Image credit: Header photo by Aaron Burden on Unsplash.


