
The story of where data governance started and how everything went wrong
Of all the tasks that I have done in the data industry, data governance has honestly been my least favorite.
Laura B. Madsen, Disrupting Data Governance
When you hear the phrase “data governance”, what’s the first thing you think? Rules or policies? Processes or management? Control?
Data governance is seen as a restrictive, bureaucratic, controlling process — a set of restrictions dropped down from on high to slow down your work. And the reality is, that’s often how it actually works inside organizations.
As someone who works in data governance, this makes me a bit sad. Governance shouldn’t be something that the humans of data have to fear. At its heart, data governance isn’t about control. It’s about helping data teams work better together.
So let’s break down why data governance is having an identity crisis, what it was actually envisioned as decades ago, and how we can save the reputations of data stewards everywhere.
Where did data governance come from?
Data governance was built on really cool principles. But if you search for the history of data governance, you probably won’t get very far. There aren’t really any think pieces tracing it back to some ridiculously early time (think data’s roots in 20,000-year-old bones or the census’ origin in ancient Egypt).
Part of the reason is that, well, data governance isn’t sexy. Few people can stifle their yawns long enough to delve into its present, let alone its past. To make things more difficult, data governance came out of data stewardship, a phrase that sounds even more dense and technical.
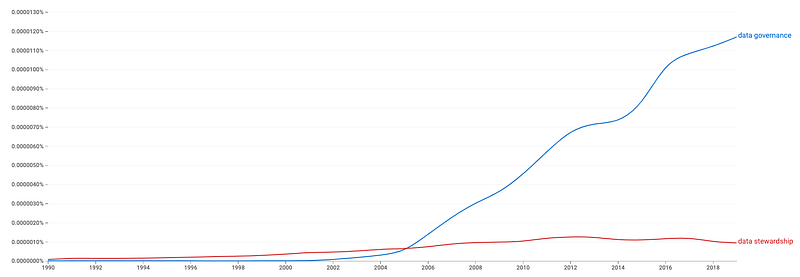
Though “data governance” took off in the mid-2000s, the idea of taming and protecting data (aka “data stewardship”) has been around since data blew up a decade earlier.
Data stewardship came about to connect the techie world of data with the non-techie world of business. As Laura Madsen wrote, “Data stewards were meant to help solidify the squishy… They speak the language of IT and translate that back to the business. The role requires the patience of a kindergarten teacher and the ability to successfully negotiate a hostage situation.”
At its core, data stewardship, and later governance, was all about collaboration and democratization. Data stewards acted as a bridge between people and process. They deftly navigated companies through the complications that arise with using data, and brought clarity and order to the intimidating new world of big data.
Data governance today: control, not collaboration
Though data governance grew out of this idea of collaboration, it’s rarely been implemented in that way. Today, it’s seen more as a way to impose control.
Data governance initiatives are usually framed around protection and risk — we have to govern our data to decrease our risk.
It’s no wonder that companies fear data risks. As data has grown, the rules and expectations around it have skyrocketed. With constant news about privacy breaches, people are becoming more attentive to how their personal data is protected. In 2018, there was a “global reckoning on data governance”, thanks to multiple massive data breaches that destroyed the credibility and stock values of brands like Equifax, Facebook, Marriott, and Yahoo. As a result, new data compliance requirements (e.g. GDPR and CCPA) are popping up every day.
Today, companies want to decrease the risk of showing confidential data to the wrong person, bad data being used to make big decisions, and violating important regulations. To prevent these missteps, data is surrounded by complex security processes and restrictions, all dictated by a distant data governance team.
More data governance, more agility?
Over the years, data governance has lost its identity. We fear it, but we should be celebrating it — because fundamentally it’s about creating better data teams, not controlling them.
In fact, the more people start trusting data governance, the more they’ll actually be able to achieve. Sounds iffy? Let’s start with an example.
At Atlan, we started out as a data team ourselves. Back then we didn’t know what data governance was. We just knew that we wanted to take on massive “data for good” projects, like creating a SDG monitoring platform for the United Nations or opening 10,000 new clean fuel distribution centers.
The problem was, every day was chaos. We had collaboration overload, where people spent more time trying to access or understand the data than actually using it. Our Slack was filled with messages like “Why is data missing for 721 geographies?” or “Why are these dashboards showing different numbers?”
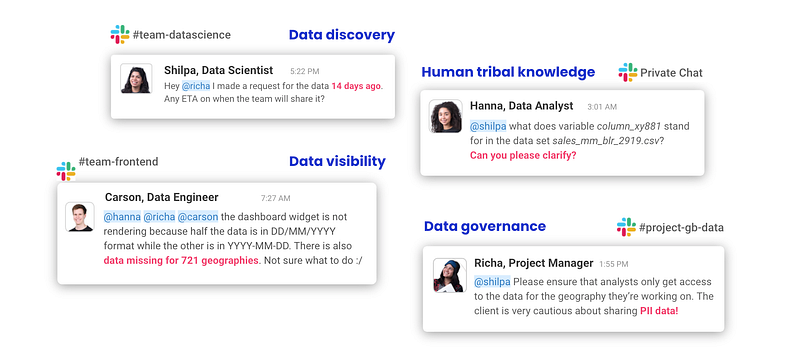
So we worked to fix these issues, building internal data tools and better processes for collaboration. Soon enough, we realized that we were accomplishing projects twice as fast with teams that were one-third our normal size. We even built India’s national data platform, done by an 8-member team in just 12 months. We never would have been able to do this without the right tooling and cultural practices governing our team and data.
I think that the more that organizations start believing in and investing in — rather than dreading — true data governance, the more they’ll be able to achieve. This means implementing governance tools and processes that are agile and collaborative, rather than a top-down governance team somewhere announcing, “Here’s how you need to think about definitions”.
The data governance renaissance in the modern data stack
In his blog about the modern data stack, Tristan talked about data governance lagging behind the rest of the modern data stack. He wrote, “Governance is a product area whose time has come… Without good governance, more data == more chaos == less trust.”
I think his words echo the broader sentiment of data teams and practitioners in the modern data stack. As data teams become more mainstream, and the modern data stack has made it easier to ingest and transform data, the lack of data governance practices is one of the top barriers preventing data teams from being agile and driving impact.
This has brought us to a moment of redemption for data governance. For the first time, the need for governance is being felt bottom-up by practitioners, instead of being enforced top-down due to regulation.
This bottom-up adoption is an opportunity for us to finally get data governance right. However, modern data governance for the modern data stack will look very different from its predecessor — and this means that we’ll have to change the way we approach data governance implementations.
The paradigm shift that data governance needs today

From data governance to “data and analytics” governance
“Data” isn’t the only asset that needs to be governed anymore.
We are moving to an ecosystem where data assets are more than just tables — they are also dashboards, codes, models, and more. All these assets need holistic forms of governance.
From a centralized approach to a decentralized, community-led approach
Centralized data steward–based, top-down governance models won’t work anymore.
The workplace is changing. Top-down cultures are getting eroded and employees crave purpose in everything they do, so just telling people to do something won’t work anymore. The data governance of the future needs to be fundamentally practitioner-led.
I almost think of this as a data community, rather than data governance, where practitioners feel a duty to create reusable assets so that they can help other community members.
From an afterthought to a part of daily workflows
In the past decade, data governance was always applied as an afterthought. Data practitioners would ship projects as they were, then go back later and add data governance requirements dictated by top-down mandates.
In the new world, data governance won’t be an afterthought. Instead, it will be a standard that’s an integral part of the “shipping workflows” for data practitioners.
Let’s rebrand data governance
The modern data stack is a master in rebranding new categories. In the past year alone, we’ve created Headless BI, Reverse ETL, Data Observability, and many more areas. The movement that has fascinated me most is “analytics engineering”, which changed the idea of data cleaning and transformation and gave a whole group of people a higher purpose.
I have an ask of our community… Let’s finally rebrand data governance and give it the rightful place and respect it deserves in our stacks. Let’s make it sound like what it’s meant to be — a set of practices that amazing data teams will follow.
I don’t quite know what the new brand and name for modern data governance should be, but it needs to align with the fundamental reorientation of governance as a bottom-up, community-led, practitioner movement.
Maybe it should be called Data Enablement, Community-Led Data Governance, or the Data-Product Mindset? Maybe the Data Steward role should be subsumed in the Data Product Manager role? Maybe Data Governance Managers should be rebranded as Data Community Managers or Data Enablement Managers and join the broader data platform teams?
There’s so much possibility, so I’d love to hear from more people. What do you think?
This article was originally published on Towards Data Science.
Header photo: Dimitry Anikin on Unsplash


