
Thanks to “Bundlegate”, it’s been a wild couple of weeks. Here’s what happened and where I think we’re going.
It’s been a wild couple of weeks in Data Twitter with another new hot debate.
As I lay tossing and turning in bed, thinking about the future of the modern data stack, I couldn’t help feel the pressure to write yet another opinion piece 😉
What actually happened?
If you were MIA, Gorkem Yurtseven kickstarted this debate with an article called “The Unbundling of Airflow”.
He explained that once small products become large platforms, they’re ripe for unbundling, or having its component functions abstracted into small, more focused products. Craigslist is a great example — its Community section has been taken over by Nextdoor, Personals by Tinder, Discussion Forums by Reddit, For Sale by OfferUp, and so on.
Gorkem argued that in the data world, the same thing is happening with Airflow.
Before the fragmentation of the data stack, it wasn’t uncommon to create end-to-end pipelines with Airflow. Organizations used to build almost entire data workflows as custom scripts developed by in-house data engineers. Bigger companies even built their own frameworks inside Airflow, for example, frameworks with dbt-like functionality for SQL transformations in order to make it easier for data analysts to write these pipelines.
Gorkem Yurtseven
Today, data practitioners have many tools under their belt and only very rarely they have to reach for a tool like Airflow… If the unbundling of Airflow means all the heavy lifting is done by separate tools, what is left behind?
As one of the data teams back in the day that ended up building our own dbt-like functionality for transformations in R and Python, Gorkem’s words hit home.
Airflow’s purposes have been built into ingestion tools (Airbyte, Fivetran, and Meltano), transformation layers (dbt), reverse ETL (Hightouch and Census), and more.
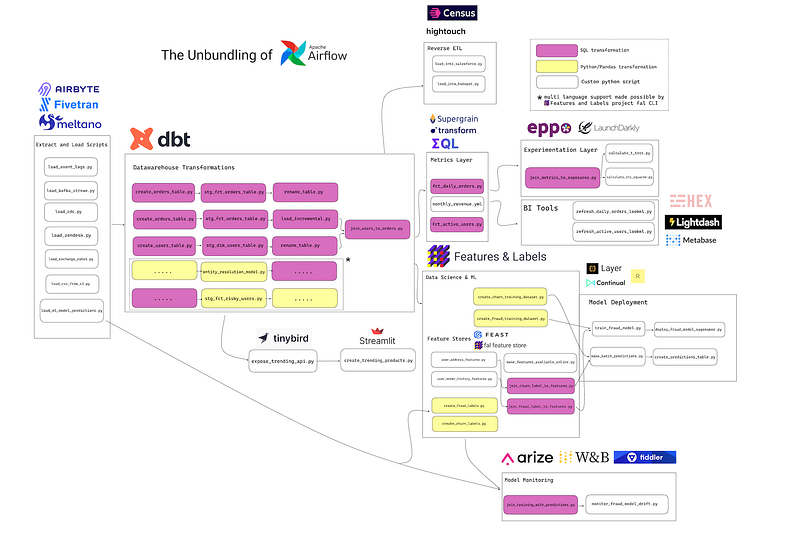
Unfortunately, this has led to a crazy amount of fragmentation in the data stack. I joke about this a lot, but honestly I feel terrible for someone buying data technology right now. The fragmentation and overlaps are mind-blowing for even an insider like me to fully grasp.
Nick Schrock from Elementl wrote a response on Dagster’s blog titled the “Rebundling of the Data Platform” that broke the data community… again. He agreed with Gorkem that the data stack was being unbundled, and said that this unbundling was creating its own set of problems.
I don’t think anyone believes that this is an ideal end state. The post itself advocates for consolidation. Having this many tools without a coherent, centralized control plane is lunacy, and a terrible endstate for data practitioners and their stakeholders… And yet, this is the reality we are slouching toward in this “unbundled” world.
Nick Schrock
Then, while I was writing this article, Ananth Packkildurai chimed in on the debate — first with a tweet and then with the latest issue of his Data Engineering Weekly newsletter.
Ananth agreed with the idea that unbundling has happened, but tied it to a larger issue. As data teams and companies have grown, data has become more complex and data orchestration, quality, lineage, and model management have become significant problems.
The data stack unbundled to solve these specific problems, which just resulted in siloed, “duct tape systems”.
The data community often compares the modern tech stack with the Unix philosophy. However, we are missing the operating system for the data. We need to merge both the model and task execution unit into one unit. Otherwise, any abstraction we build without the unification will further amplify the disorganization of the data. The data as an asset will remain an aspirational goal.
Ananth Packkildurai
So… what’s my take? Where are we headed?
There are two kinds of people in the data world — those who believe in bundling and those who think unbundling is the future.
I believe that the answer lies somewhere in the middle. Here are some of my predictions and takes.
1. There will absolutely be more bundling from our current version of the modern data stack.
The current version of the modern data stack, with a new company launching every 45 minutes, is unsustainable. We’re absolutely in the middle of the golden era of innovation in the MDS, funded quite generously by Venture Capital $$ — all in search for the next Snowflake. I’ve heard stories of perfectly happy (data) product managers in FAANG companies being handed millions of dollars to “try out any idea”.
This euphoria has had big advantages. A ton of smart people are solving data teams’ biggest tooling challenges. Their work has made the modern data stack a thing. It has made the “data function” more mainstream. And, most importantly, it has spurred innovation.
But, honestly, this won’t last forever. The cash will dry up. Consolidation, mergers, and acquisitions will happen. (We’ve already started seeing glimpses of this with dbt’s move into the metrics layer and Hevo’s move to introduce reverse ETL along with their data ingestion product.) Most importantly, customers will start demanding less complexity as they make choices about their data stack. This is where bundling will start to win.
2. However, we never will (and shouldn’t ever) have a fully bundled data stack.
Believe it or not, the data world started off with the vision of a fully bundled data stack. A decade ago, companies like RJ Metrics and Domo aimed to create their own holistic data platforms.
The challenge with a fully bundled stack is that resources are always limited and innovation stalls. This gap will create an opportunity for unbundling, and so I believe we’ll go through cycles of bundling and unbundling. That being said, I believe that the data space in particular has peculiarities that make it difficult for bundled platforms to truly win.
My co-founder Varun and I spend a ton of time thinking about the DNA of companies or products. We think it’s important — perhaps the most important thing that defines who succeeds in a category of product.
Let’s look at the cloud battles. AWS, for example, has always been largely focused on scale —something they do a great job in. On the other hand, Azure coming from Microsoft has always had a more end-user-focused DNA, stemming from its MS Office days. It’s no surprise that AWS doesn’t do as well in creating world-class, user experience–focused applications as Azure, while Azure doesn’t do as well in scaling technical workloads as AWS.
Before we can talk about the DNA of the data world, we have to acknowledge that its sheer diversity. The humans of data are data engineers, analysts, analytics engineers, scientists, product managers, business analysts, citizen scientists, and more. Each of these people has their own favorite and equally diverse data tools, everything from SQL, Looker, and Jupyter to Python, Tableau, dbt, and R. And data projects have their own technical requirements and peculiarities — some need real-time processing while some need speed for ad-hoc analysis, leading to a whole host of data infrastructure technologies (warehouses, lakehouses, and everything in between).
Because of this diversity, the technology for each of these different personas and use cases each will have very different DNA. For example, a company building BI should be focused on the end-user experience, while company building a data warehouse should be focused on reliability and scaling.
This is why I believe that while bundling will happen, it will only happen in spaces where products’ fundamental DNA is similar. For example, we will likely see data quality merge with data transformation, and potentially data ingestion merge with reverse ETL. However, we probably won’t see data quality bundled with reverse ETL.
3. Metadata holds the key to unlocking harmony in a diverse data stack.
While we’ll see more consolidation, the fundamental diversity of data and the humans of data is never going away. There will always be use cases where Python is better than SQL or real-time processing is better than batch, and vice versa.
If you understand this fundamental reality, you have to stop searching for a future with a universal “bundled data platform” that works for everyone — and instead find ways for the diverse parts of our unbundled data stack to work together, in perfect harmony.
Data is chaos. That doesn’t mean that work needs to be.
I believe that the key to helping our data stack work together is in activating metadata. We’ve only scratched the surface of what metadata can do for us, but using metadata to its fullest potential can fundamentally change how our data systems operate.
Today, metadata is used for (relatively) simplistic use cases like data discovery and data catalogs. We take a bunch of metadata from a bunch of tools and put it into a tool we call the data catalog or the data governance tool. The problem with this approach is that it basically adds one more siloed tool to an already siloed data stack.
Instead, take a moment and imagine what a world could look like if you could have a Segment or Zapier-like experience in the modern data stack — where metadata can create harmony across all our tools and power perfect experiences.
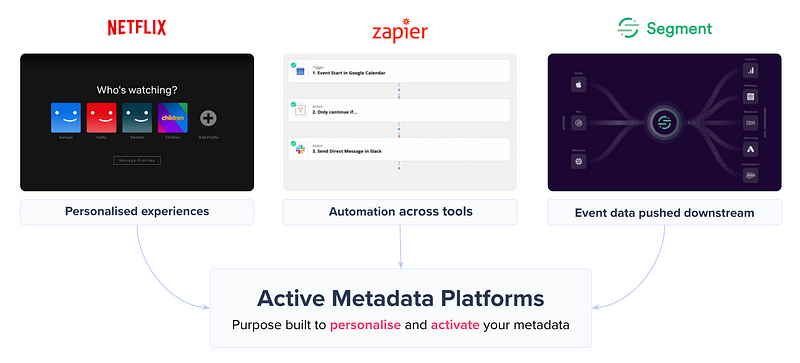
For example, one use case for metadata activation could be as simple as notifying downstream consumers of upstream changes.
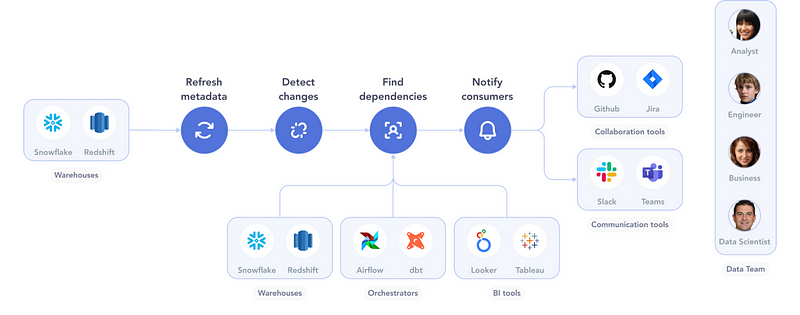
A Zap-like workflow for this simple process could look like this:
When a data store changes…
- Refresh metadata: Crawl the data store to retrieve its updated metadata.
- Detect changes: Compare the new metadata against the previous metadata. Identify any changes that could cause an impact — adding or removing columns, for example.
- Find dependencies: Use lineage to find users of the data store. These could include transformation processes, other data stores, BI dashboards, and so on.
- Notify consumers: Notify each consumer through their preferred communication channel — Slack, Jira, etc.
This workflow could also be incorporated as part of the testing phases of changing a data store. For example, the CI/CD process that changes the data store could also trigger this workflow. Orchestration can then notify consumers before production systems change.
In Stephen Bailey’s words, “No one knows what the data stack will look like in ten years, but I can guarantee you this: metadata will be the glue.”
I think this debate is far from over, but it’s amazing how many insights and hot takes (like this one) that it has stirred up.
To keep the discussion going, we just hosted Gorkem Yurtseven, Nick Schrock, and Ananth Packkildurai for our Great Data Debate.
This article was originally published on Towards Data Science.
Header image: Bakhrom Tursunov on Unsplash


