
Delta Lake is now fully open-sourced, Unity Catalog goes GA, Spark runs on mobile, and much more.
San Francisco was buzzing last week. The Moscone Center was full, Ubers were on perpetual surge, and data t-shirts were everywhere you looked.
That’s because, on Monday June 27, Databricks kicked off the Data + AI Summit 2022, finally back in person. It was fully sold out, with 5,000 people attending in San Francisco and 60,000 joining virtually.
The summit featured not one but four keynote sessions, spanning six hours of talks from 29 amazing speakers. Through all of them, big announcements were dropping fast — Delta Lake is now fully open-source, Delta Sharing is GA (general availability), Spark now works on mobile, and much more.
Here are the highlights you should know from the DAIS 2022 keynote talks, covering everything from Spark Connect and Unity Catalog to MLflow and DBSQL.
P.S. Want to see these keynotes yourself? They’re available on-demand for the next two weeks. Start watching here.

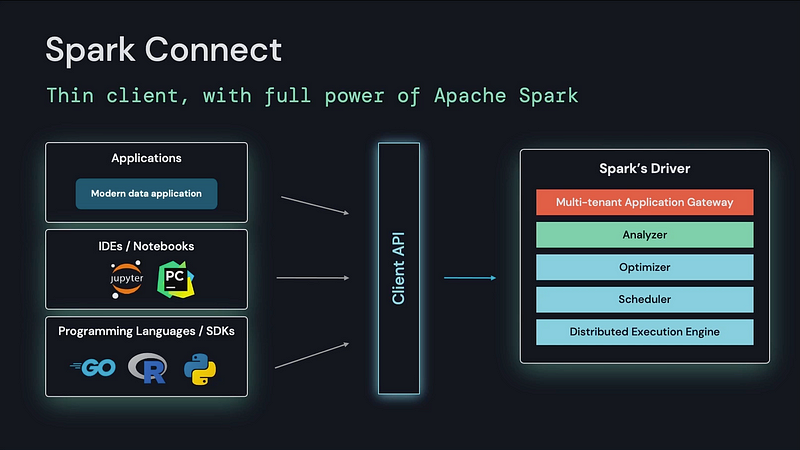
Spark Connect, the new thin client abstraction for Spark
Apache Spark — the data analytics engine for large-scale data, now downloaded over 45 million times a month — is where Databricks began.
Seven years ago, when we first started Databricks, we thought it would be out of the realm of possibility to run Spark on mobile… We were wrong. We didn’t know this would be possible. With Spark Connect, this could become a reality.
Reynold Xin (Co-founder and Chief Architect)
Spark is often associated with big data centers and clusters, but data apps don’t live in just big data centers anymore. They live in interactive environments like notebooks and IDEs, web applications, or even edge devices like Raspberry Pis and iPhones. However, you don’t generally see Spark in those places. That’s because Spark’s monolith driver makes it hard to embed Spark in remote environments. Instead, developers are embedding applications in Spark, leading to issues with memory, dependencies, security, and more.
To improve this experience, Databricks launched Spark Connect, which Reynold Xin called “the largest change to [Spark] since the project’s inception”.
With Spark Connect, users will be able to access Spark from any device. The client and server are now decoupled in Spark, allowing developers to embed Spark into any application and expose it through a thin client. This client is programming language–agnostic, works even on devices with low computational power, and improves stability and connectivity.
Learn more about Spark Connect here.
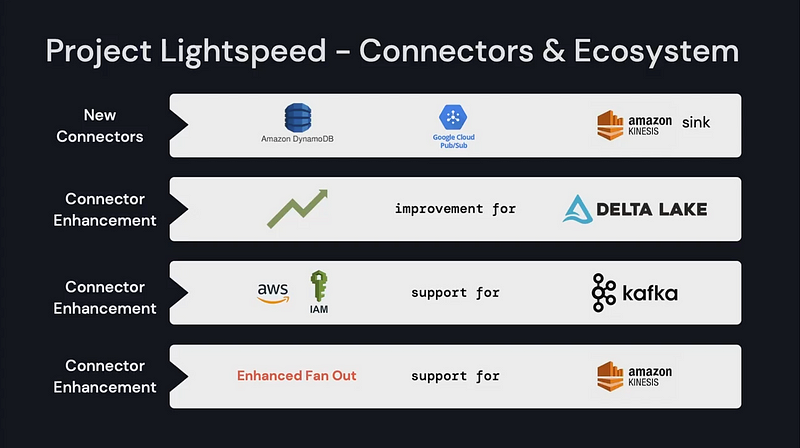
Project Lightspeed, the next generation of Spark Structured Streaming
Streaming is finally happening. We have been waiting for that year where streaming workloads take off, and I think last year was it. I think it’s because people are moving to the right of this data/AI maturity curve, and they’re having more and more AI use cases that just need to be real-time.
Ali Ghodsi (CEO and Co-founder)
Today, more than 1,200 customers run millions of streaming applications daily on Databricks. To help streaming grow along with these new users and use cases, Karthik Ramasamy (Head of Streaming) announced Project Lightspeed, the next generation of Spark Structured Streaming.
Project Lightspeed is a new initiative that aims to make stream processing faster and simpler. It will focus on four goals:
- Predictable low latency: Reduce tail latency up to 2x through offset management, asynchronous checkpointing, and state checkpointing frequency.
- Enhanced functionality: Add advanced capabilities for processing data (e.g. stateful operators, advanced windowing, improved state management, asynchronous I/O) and make Python a first-class citizen through an improved API and tighter package integrations.
- Improved operations and troubleshooting: Enhance observability and debuggability through new unified metric collection, export capabilities, troubleshooting metrics, pipeline visualizations, and executor drill-downs.
- New and improved connectors: Launch new connectors (e.g. Amazon DynamoDB) and improve existing ones (e.g. AWS IAM auth support in Apache Kafka).
Learn more about Project Lightspeed here.
MLflow Pipelines with MLflow 2.0
MLflow is an open-source MLOps framework that helps teams track, package, and deploy machine learning applications. Over 11 million people download it monthly, and 75% of its public roadmap was completed by developers outside of Databricks.
Organizations are struggling to build and deploy machine learning applications at scale. Many ML projects never see the light of day in production.
Kasey Uhlenhuth (Staff Product Manager)
According to Kasey Uhlenhuth, there are three main friction points on the path to ML production: the tedious work of getting started, the slow and redundant development process, and the manual handoff to production. To solve these, many organizations are building bespoke solutions on top of MLflow.
Coming soon, MLflow 2.0 aims to solve this with a new component — MLflow Pipelines, a structured framework to help accelerate ML deployment. In MLflow, a pipeline is a pre-defined template with a set of customizable steps, built on top of a workflow engine. There are even pre-built pipelines to help teams get started quickly without writing any code.
Learn more about MLflow Pipelines.

Delta Lake 2.0 is now fully open-sourced
Delta Lake is the foundation of the lakehouse, an architecture that unifies the best of data lakes and data warehouses. Powered by an active community, Delta Lake is the most widely used lakehouse format in the world with over 7 million downloads per month.
Delta Lake went open-source in 2019. Since then, Databricks has been building advanced features for Delta Lake, which were only available inside of its product… until now.
As Michael Armbrust announced amidst cheers and applause, Delta Lake 2.0 is now fully open-sourced. This includes all of the existing Databricks features that dramatically improve performance and manageability.
Delta is now one of the most feature-full open-source transactional storage systems in the world.
Michael Armbrust (Distinguished Software Engineer)
Learn more about Delta Lake 2.0 here.

Unity Catalog goes GA (general availability)
Governance for data and AI gets complex. With so many technologies involved with data governance, from data lakes and warehouses to ML models and dashboards, it can be hard to set and maintain fine-grained permissions for diverse people and assets across your data stack.
That’s why last year Databricks announced Unity Catalog, a unified governance layer for all data and AI assets. It creates a single interface to manage permissions for all assets, including centralized auditing and lineage.
Since then, there have been a lot of changes to Unity Catalog — which is what Matei Zaharia (Co-Founder and Chief Technologist) talked about during his keynote.
- Centralized access controls: Through a new privilege inheritance model, data admins can give access to thousands of tables or files with a single click or SQL statement.
- Automated real-time data lineage: Just launched, Unity Catalog can track lineage across tables, columns, dashboards, notebooks, and jobs in any language.
- Built-in search and discovery: This now allows users to quickly search through the data assets they have access to and find exactly what they need.
- Five integration partners: Unity Catalog now integrates with best-in-class partners to set sophisticated policies, not just in Databricks but across the modern data stack.
Unity Catalog and all of these changes are going GA (general availability) in the coming weeks.
Learn more about updates to Unity Catalog here.

P.S. Atlan is a Databricks launch partner and just released a native integration for Unity Catalog with end-to-end lineage and active metadata across the modern data stack. Learn more here.
Serverless Model Endpoints and Model Monitoring for ML
IDC estimated that 90% of enterprise applications will be AI-augmented by 2025. However, companies today struggle to go from their small early ML use cases (where the initial ML stack is separate from the pre-existing data engineering and online services stacks) to large-scale production ML (with data and ML models unified on one stack).
Databricks has always supported datasets and models within its stack, but deploying these models could be a challenge.
To solve this, Patrick Wendell (Co-founder and VP of Engineering) announced the launch of Services, full end-to-end deployment of ML models inside a lakehouse. This includes Serverless Model Endpoints and Model Monitoring, both currently in Private Preview and coming to Public Preview in a few months.
Learn more about Serverless Model Endpoints and Model Monitoring.

Delta Sharing goes GA with Marketplace and Cleanrooms
Matei Zaharia dropped a series of major announcements about Delta Sharing, an open protocol for sharing data across organizations.
- Delta Sharing goes GA: After being announced at last year’s conference, Delta Sharing is going GA in the coming weeks with a suite of new connectors (e.g. Java, Power BI, Node.js, and Tableau), a new “change data feed” feature, and one-click data sharing with other Databricks accounts. Learn more.
- Launching Databricks Marketplace: Built on Delta Sharing to further expand how organizations can use their data, Databricks Marketplace will create the first open marketplace for data and AI in the cloud. Learn more.
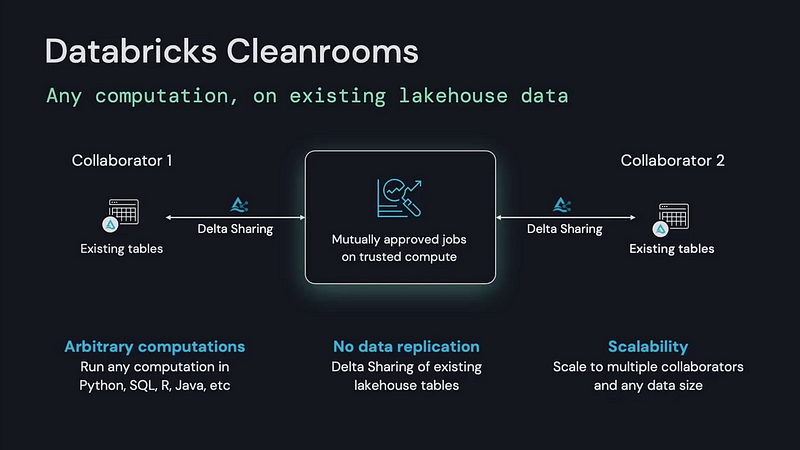
- Launching Databricks Cleanrooms: Built on Delta Sharing and Unity Catalog, Databricks Cleanrooms will create a secure environment that allows customers to run any computation on lakehouse data without replication. Learn more.
Partner Connect goes GA
The best lakehouse is a connected lakehouse… With Legos, you don’t think about how the blocks will connect or fit together. They just do… We want to make connecting data and AI tools to your Lakehouse as seamless as connecting Lego blocks.
Zaheera Valani (Senior Director of Engineering)
First launched in November 2021, Partner Connect helps users easily discover and connect data and AI tools to the lakehouse.
Zaheera Valani kicked off her talk with a major announcement — Partner Connect is now generally available for all customers, including a new Connect API and open-source reference implementation with automated tests.
Learn more about Partner Connect’s GA.
Enzyme, auto-optimization for Delta Live Tables
Only released a few months ago into GA itself, Delta Live Tables is an ETL framework that helps developers build reliable pipelines. Michael Armbrust took the stage to announce major changes to DLT, including the launch of Enzyme, an automatic optimizer that reduces the cost of ETL pipelines.
- Enhanced autoscaling (in preview): This auto-scaling algorithm saves infrastructure costs by optimizing cluster optimization while minimizing end-to-end latency.
- Change Data Capture: The new declarative
APPLY CHANGES INTOlets developers detect source data changes and apply them to affected data sets. - SCD Type 2: DLT now supports SCD Type 2 to maintain a complete audit history of changes in the ELT pipeline.
Rivian took a manual [ETL] pipeline that actually used to take over 24 hours to execute. They were able to bring it down to near real-time, and it executes at a fraction of the cost.
Michael Armbrust (Distinguished Software Engineer)
Learn more about Enzyme and other DLT changes.

Photon goes GA, and Databricks SQL gets new connectors and upgrades
Shant Hovsepian (Principal Engineer) announced major changes for Databricks SQL, a SQL warehouse offering on top of the lakehouse.
- Databricks Photon goes GA: Photon, the next-gen query engine for the lakehouse, is now generally available on the entire Databricks platform with Spark-compatible APIs. Learn more.
- Databricks SQL Serverless on AWS: Serverless compute for DBSQL is now in Public Preview on AWS, with Azure and GCP coming soon. Learn more.
- New SQL CLI and API: To help users run SQL from anywhere and build custom data applications, Shant announced the release of a new SQL CLI (command-line interface) with a new SQL Execution REST API in Private Preview. Learn more.
- New Python, Go, and Node.js connectors: Since its GA in early 2022, the Databricks SQL connector for Python averages 1 million downloads each month. Now, Databricks has completely open-sourced that Python connector and launched new open-source, native connectors for Go and Node.js. Learn more.
- New Python User Defined Functions: Now in Private Preview, Python UDFs let developers run flexible Python functions from within Databricks SQL. Sign up for the preview.

Databricks Workflows
Databricks Workflows is an integrated orchestrator that powers recurring and streaming tasks (e.g. ingestion, analysis, and ML) on the lakehouse. It’s Databricks’ most used service, creating over 10 million virtual machines per day.
Stacy Kerkela (Director of Engineering) demoed Workflows to show some of its new features in Public Preview and GA:
- Repair and Rerun: If a workflow fails, this capability allows developers to only save time by only rerunning failed tasks.
- Git support: This support for a range of Git providers allows for version control in data and ML pipelines.
- Task values API: This allows tasks to set and retrieve values from upstream, making it easier to customize one task to an earlier one’s outcome.
There are also two new features in Private Preview:
- dbt task type: dbt users can run their projects in production with the new dbt task type in Databricks Jobs.
- SQL task type: This can be used to orchestrate more complex groups of tasks, such as sending and transforming data across a notebook, pipeline, and dashboard.
Learn more about new features in Workflows.

As Ali Ghodsi said, “A company like Google wouldn’t even be around today if it wasn’t for AI.”
Data runs everything today, so it was amazing to see so many changes that will make life better for data and AI practitioners. And those aren’t just empty words. The crowd at the Data + AI Summit 2022 was clearly excited and broke into spontaneous applause and cheers during the keynotes.
These announcements were especially exciting for us as a proud Databricks partner. The Databricks ecosystem is growing quickly, and we’re so happy to be part of it. The world of data and AI is just getting hotter, and we can’t wait to see what’s up next!
Did you know that Atlan is a Databricks Unity Catalog launch partner?
Learn more about our partnership with Databricks and native integration with Unity Catalog, including end-to-end column-level lineage across the modern data stack.
This article was co-written by Prukalpa Sankar and Christine Garcia.


