
Nothing is more frustrating than wrapping up a lengthy data collection exercise, aggregating all the data and looking through it, only to find missing data. At best, these missing values are a nuisance that can be fixed with a bit of work. At worst, they pose an intimidating threat to data quality and your sample size.
How can you assess how bad your missing data is, and how should you deal with it? Keep reading for 4 methods you can use during data cleaning to deal with different types of missing data.
Independent and Dependent Variables
Before we can talk about missing data, we have to first talk about the two types of data that might be missing.
Data has two kinds of variables — independent (or predictor) and dependent (or response) variables. Independent variables influence or affect the values of the dependent variables.
Consider the following table containing a few examples of independent and dependent variables in different contexts:

The objective of a study is usually to learn more about the behavior of, or establish patterns in, the values of dependent variables, and then use independent variables to explain their behavior.
4 Ways to Deal with Missing Values
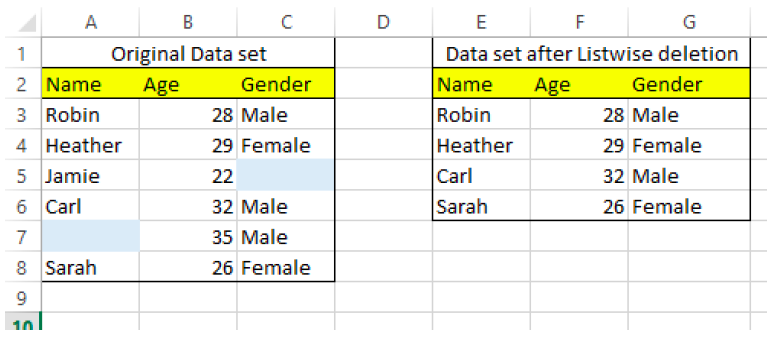
Listwise Deletion
Pro: Easy to apply, does not tamper with the data.
Con: Can greatly reduce your sample size.
In the listwise deletion method, all rows that have one or more column values missing are deleted.
Missing values in dependent variables would often require you to delete the entire record, since it cannot contribute to the research. Alternatively, for a particular dependent variable, too many missing independent variables can also result in no meaningful insights, which would also require you to delete the entire record.
Mean/Median/Mode Imputation
Pro: No loss in sample size, no skewing of data.
Con: Cannot be applied on categorical variables, i.e. non-numerical/qualitative data.
In the mean/median/mode imputation method, all missing values in a particular column are substituted with the mean/median/mode, which is calculated using all the values available in that column. You can use appropriate functions in Excel to compute the mean/median/mode by simply plugging in the range of the column into the input of the function.
Mean
Mean (commonly known as average) is equal to the sum of all values in the column divided by the number of values present in the column. In Excel, you can use the AVERAGE() function to compute the mean.
Median
Median is the “middle” value amongst the range of values. To compute the median of a range containing ‘n’ number of values, you need to sort these ‘n’ values in ascending order.
- For an odd number of observations, the median is the ((n+1)/2)th value. For example, the median for a sorted list of 13 observations is the 7th value.
- For an even number of observations, the median is the average of the (n/2)th and ((n+2)/2)th values. For example, the median for a sorted list of 12 observations is the average of the 6th and 7th values.
In Excel, you can use the MEDIAN() function to compute the median.
Mode
Mode is the value that occurs the most often in the range of values. In Excel, you can use the MODE() function to compute the mode.
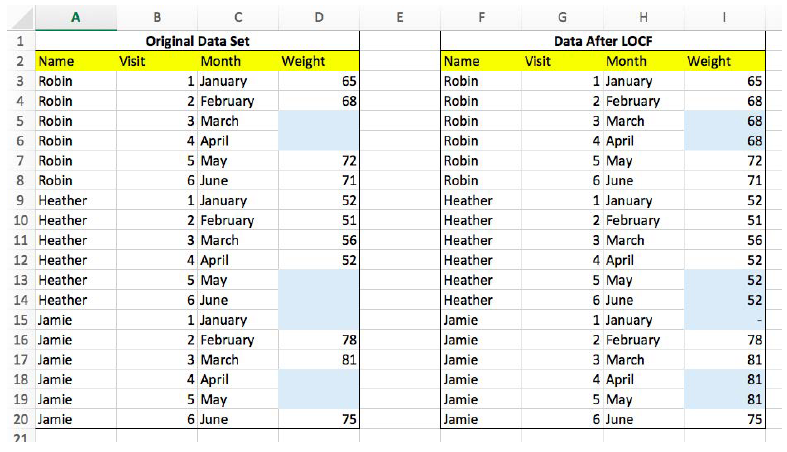
Last Observation Carried Forward (LOCF)
Pro: Ensures no sample size loss from dropouts
Con: Can only be applied to longitudinal data analysis
LOCF is a technique specific to longitudinal data analysis. This is a crude method where a missing value for a particular row is filled in with a value available from the previous stages.
Resurveying
Pro: No loss in sample size, ensures that the missing data point is filled accurately.
Con: Takes additional time and money to send surveyors back to select respondents.
Resurveying a data point — i.e. sending a surveyor back to a respondent to re-collect a data point — is the most foolproof way of dealing with missing data. Unlike the methods above, it ensures that a missing data point is filled with an accurate, rather than approximate, value.
Resurveying can be time-consuming. However, it becomes easier with mobile-based data collection applications like Collect, which allows administrators to flag suspect data points and send surveyors to re-collect those data points within the original survey.



3 Comments
Interpolation should work well too ?! I have used PDE’s for interpolating nans , as my system was irregularly sampled. Your thoughts on this ?
Interpolation works pretty well. As Harish has stated. I oftentimes use interpolation in the event of missing data.
this is very useful resource. thanks