
When discussing data collection, outliers inevitably come up. What is an outlier exactly? It’s a data point that is significantly different from other data points in a data set. While this definition might seem straightforward, determining what is or isn’t an outlier is actually pretty subjective, depending on the study and the breadth of information being collected.
So what’s the best way to handle outliers? Below are some tips that can help to make handling them a little bit less elusive.
How to detect different types of outliers
As mentioned above, detecting outliers can be a somewhat subjective practice. But there are some things that, generally speaking, will help you to determine a significantly different data point.
Use common sense
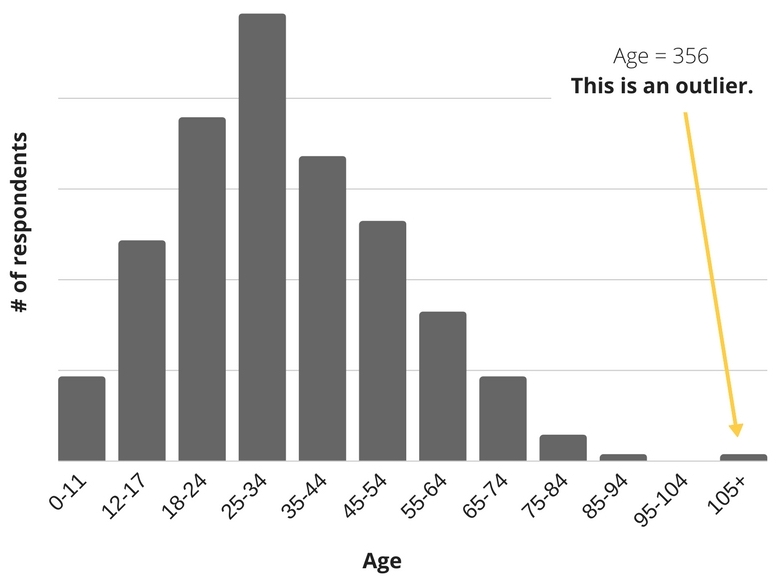
With data where you already know the distribution (like people’s ages), you can use common sense to find outliers that were incorrectly recorded. For example, you know that 356 is not a valid age, while 45 is.
That example is univariate, meaning that it has just one variable — age. What if you have multiple variables (i.e. multivariate data)? How can you find outliers?
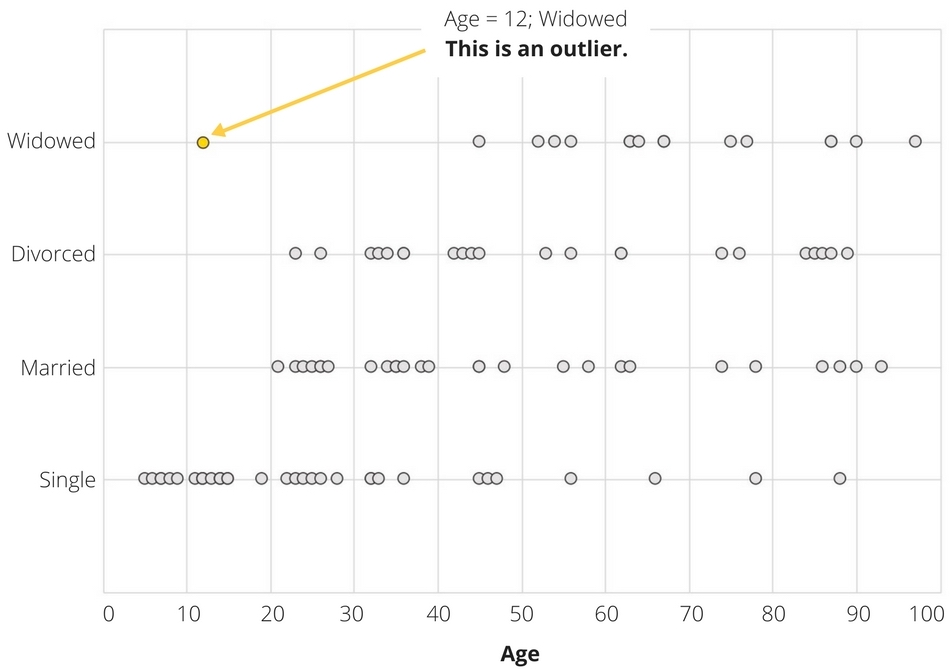
Looking at variables together can help you spot common-sense outliers. Say a study is using both people’s ages and marital status to draw conclusions. If you look at variables separately, you might miss outliers. For example, “12 years old” isn’t an outlier and “widow” isn’t an outlier, but we know that a 12-year-old widow is likely an outlier, thanks to common sense.
Another source of “common sense” outliers is data that was accidentally reported in the wrong units. Say, for example, your data reports the minutes it took for someone to complete a task. The task took most people 3 to 10 minutes, but there is also a data point of 300. Common sense tells us this could be a data point that was accidentally recorded in seconds — aka 5 minutes.
Visually find outliers by plotting data
A histogram is the best way to visualize univariate (single variable) data to find outliers. A histogram divides the range of values into various groups, and then shows how many times the data falls into each group on a bar chart. Arrange the data groups sequentially, and it should be easy to spot outliers on either the far left or far right sides of the histogram.
For multivariate data, scatterplots can be very effective. Scatterplots show a collection of data points, where the x-axis (horizontal) represents the independent variable and the y-axis (vertical) represents the dependent variable. Scatterplots can easily show the “12-year-old widow” from in the example above as an outlier separate from the rest of the grouped data points.
Use statistical tests
These tests effectively compare data within in a set to help determine outliers. Various statistical tests include Pierce’s Criterion, Chauvenet’s Criterion, Grubb’s test for outliers, Dixon Q’s test, and others. These are certainly helpful but they can also be time-consuming.
Read more about simple but effective technique for finding outliers — inner and outer fences.
When to drop or keep outliers
Sometimes outliers indicate a mistake in data collection. Other times, though, they can influence a data set, so it’s important to keep them to better understand the big picture. Below are some quick examples regarding when you should and shouldn’t drop outliers.
Drop an outlier if:
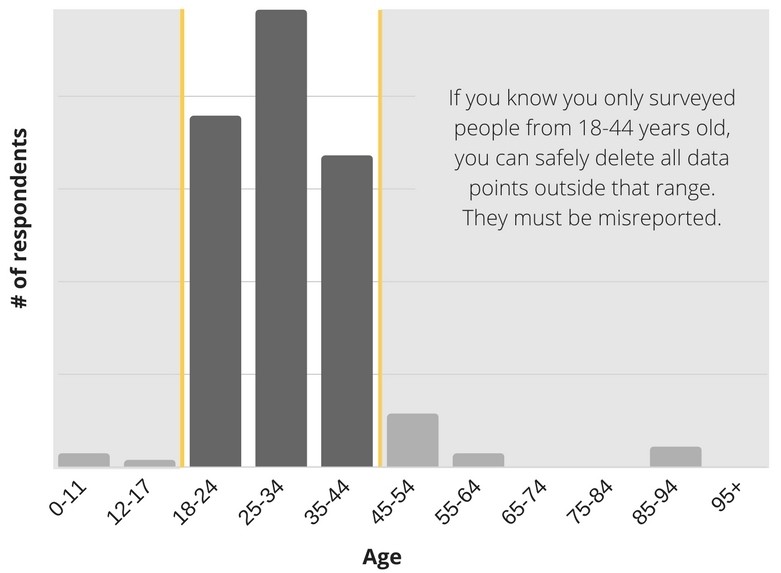
- You know that it’s wrong. For example, if you have a really good sense of what range the data should fall in, like people’s ages, you can safely drop values that are outside of that range.
- You have a lot of data, so your sample won’t be hurt by dropping a questionable outlier.
- You can go back and recollect or verify the questionable data point.
Don’t drop an outlier if:
- Your results are critical, so even small changes will matter a lot. For example, you can feel better about dropping outliers about people’s favorite TV shows, not about the temperatures at which airplane seals fail.
- There are a lot of outliers. Outliers are rare by definition. If, for example, 30% of your data is outliers, then it actually means that there’s something interesting going on with your data that you need to look further into.
Examine an outlier further if:
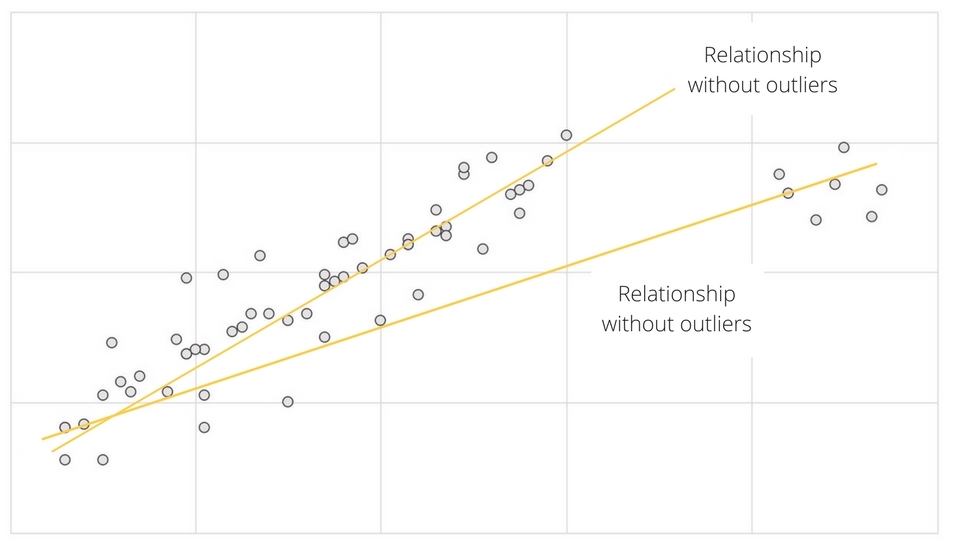
- It changes your results. Run your analysis both with and without an outlier — if there’s a substantial change, you should be careful to examine what’s going on before you delete the outlier.
- If the outlier creates a relationship where there isn’t one otherwise, either delete the outlier or don’t use those results. In general, an outlier shouldn’t be the basis for your results.

- If the outlier skews an existing statistical relationship, check it out further. Is the outlier adding nuance or additional information to this relationship, or is it disrupting the line of an otherwise strong relationship?
How to handle a data set with outliers
Knowing what to do with a data set once outliers are determined is just as important as finding the outliers in the first place. Below are some general parameters to keep a data set reliable and usable once you find outliers.
If you drop outliers:
Don’t forget to trim your data or fill the gaps:
- Trim the data set. Set your range for what’s valid (for example, ages between 0 and 100, or data points between the 5th to 95th percentile), and consistently delete any data points outside of the range.
- Trim the data set, but replace outliers with the nearest “good” data, as opposed to truncating them completely. (This called Winsorization.) For example, if you thought all data points above the 95th percentile were outliers, you could set them to the 95th percentile value.
- Replace outliers with the mean or median (whichever better represents for your data) for that variable to avoid a missing data point.
If you keep outliers:
- Run and publish two analyses, one with the outliers and one without. Being transparent in the final report is a great way to make sure that your final analysis is reliable.
- Separate the outliers from your data and run different analyses. (This is relevant when outliers are grouped.) For example, if you’re looking at people’s charitable giving relative to their income, you might find some super high Bill Gates or Warren Buffet-level outliers. Including these in your analysis of the average person’s charitable giving would skew your results. In that case, separate out the super high-income people from the rest, and run analyses separately.
- Transform the data. For example, run your analysis with the percentile ranges or log value of a data point, rather than the data points’ values.
- Run more rigorous forms of analysis that are more resistant to outliers. One example is Principal Component Analysis, which is used to emphasize variation and bring out strong patterns in a data set. (Learn more about PCA here.)
While outliers can be seem like a burden, they are important to acknowledge. Ignoring them can skew your data or make you miss a problem you might not have otherwise expected. Using the above tips can help to make outliers feel less elusive and help data analysts more adept at handling outliers effectively.
Photo by Randy Fath on Unsplash


