
What is an outlier? In short, it’s a data point that is significantly different from other data points in a data set. The long story? There isn’t a strong mathematical definition for what is or isn’t an outlier. In the end, detecting and handling outliers is often a somewhat subjective exercise.
So how can you dive into a new data set, find the outliers, and clean them? Keep reading for tips and tricks to help you detect and handle outliers.
What Are Outliers and Why Are They Important?
Imagine that you generally keep spare change and small bills in your pocket. If you reach in your pocket and find a $1 bill, a quarter, a dime, and 3 pennies, you won’t be surprised. If you find a $100 bill, you will certainly be surprised.
That $100 bill is an outlier — a data point that is significantly different from other data points.
Outliers can represent accurate or inaccurate data. For example, if you reported finding a $200 bill in your pocket, people would rightly ignore your story. That outlier would be inaccurate, since $200 bills do not exist. This is likely to be misreporting for a $20 bill.
However, a report of finding a $100 bill could be an accurate outlier. While that data point is abnormal, it is possible. Perhaps you had just withdrawn $100 from an ATM with no small bills.
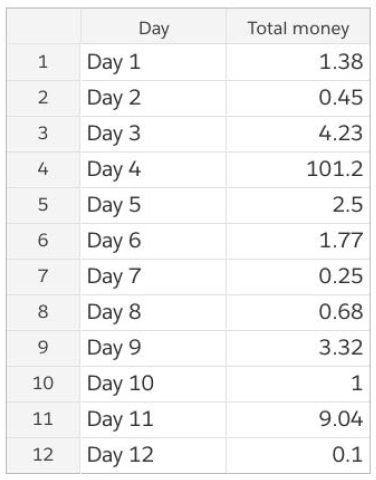
It is important to find and deal with outliers, since they can skew interpretation of the data. For example, imagine that you want to know how much money you keep in your pocket each day. At the end of each day, you empty your pockets, count the money, and record the total. The results after 12 days are in the table to the right.
Day 4 is clearly an outlier. If you exclude Day 4 from your calculations, you would conclude that you keep an average of $2.25 in your pocket. However, if you don’t exclude Day 4, the average money in your pocket would be $10.49. These are vastly different results.
How to Find Outliers
Outliers are inevitable, especially for large data sets. On their own, they are not problematic. However, in the context of the larger data set, it is essential to identify, verify, and accordingly deal with outliers to ensure that your data interpretation is as accurate as possible.
The first step in dealing with outliers is finding them. There are two ways to approach this.
Visualize the Data
Depending on your data set, you can use some simple tools to visualize your data and spot outliers visually.
Histogram: A histogram is the best way to check univariate data — data containing a single variable — for outliers. A histogram divides the range of values into various groups (or buckets), and then shows the frequency — how many times the data falls into each group — through a bar graph. Assuming that these buckets are arranged in increasing order, you should be able to spot outliers easily at the far left (very small values) or at the far right (very large values).
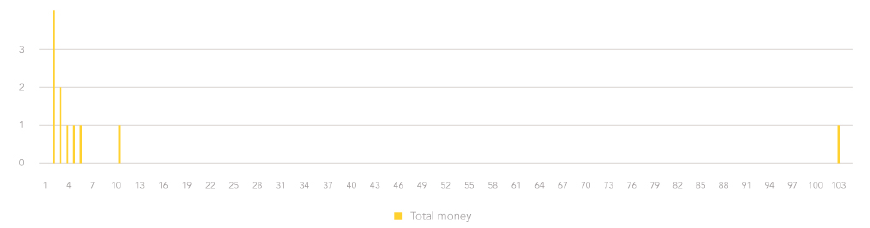
This histogram of our pocket change example shows an outlier on the far right for Day 4 ($101.2).
Scatter Plot: A scatter plot (also called a scatter diagram or scatter graph) shows a collection of points on an x-y coordinate axis, where the x-axis (horizontal axis) represents the independent variable and the y-axis (vertical axis) represents the dependent variable.
A scatter plot is useful to find outliers in bivariate data (data with two variables). You can easily spot the outliers because they will be far away from the majority of points on the scatter plot.
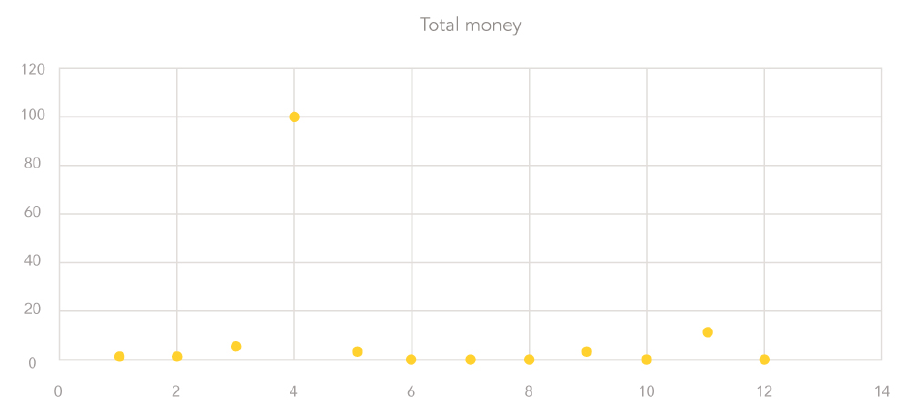
This scatter plot of our pocket change example shows an outlier — far away from all the other points — for Day 4 ($101.2).
The Statistical Way
Using statistical techniques is a more thorough approach to identifying outliers. There are several advanced statistical tools and packages that you could use to identify outliers.
Here we’ll talk about a simple, widely used, and proven technique to identify outliers.
Step 1: Sort the Data
Sort the data in the column in ascending order (smallest to largest). You can do this in Excel by selecting the “Sort & Filter” option in the top right in the home toolbar.
Sorting the data helps you spot outliers at the very top or bottom of the column. However, there could be more outliers that might be difficult to catch.
Step 2: Quartiles
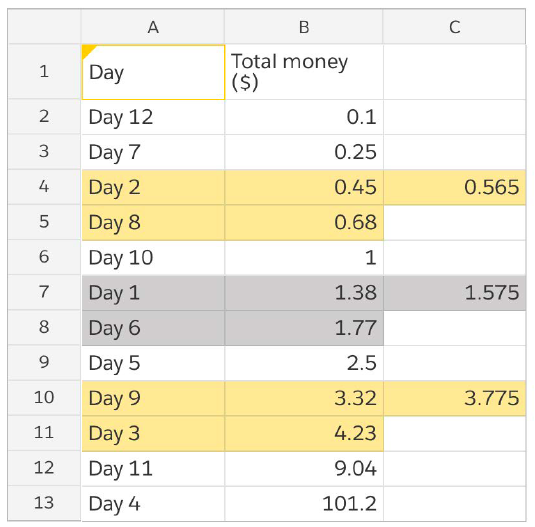
In any ordered range of values, there are three quartiles that divide the range into four equal groups. The second quartile (Q2) is nothing but the median, since it divides the ordered range into two equal groups. For an odd number of observations, the median is equal to the middle value of the sorted range.
In this example, since we have an even number of observations (12), we need to calculate the average of the sixth and seventh-position values in the ordered range — that is, the average of 1.38 and 1.77. The median of the range works out to be 1.575.
To calculate the first (Q1) and third quartiles (Q3), you need to simply calculate the medians of the first half and second half respectively. In this case, Q1 is 0.565 and Q3 is 3.775.
Step 3: Inner and Outer Fences
The inner and outer fences are ranges that you can calculate using the Q1 and Q3. To do this, you need to first calculate the interquartile range — the difference between Q1 and Q3. In this case, Q3-Q1 = 3.21.
A data point that falls outside the inner fence is called a minor outlier.
Inner Fence:
Lower bound = Q1 - (1.5 * (Q3-Q1))
Upper bound = Q3 + (1.5 * (Q3-Q1))
In our example, the bounds for the inner fence are:
Lower Bound = 0.565 - (1.5*3.21) = -4.25
Upper Bound = 3.775 + (1.5*3.21) = 8.59
The data points for Day 11 and Day 4, that is 9.04 and 101.20 respectively, qualify as minor outliers.
A data point that falls outside the outer fence is called a major outlier.
Outer Fence:
Lower bound = Q1 - (3 * (Q3-Q1))
Upper bound = Q3 + (3 * (Q3-Q1))
In our example, the bounds for the outer fence are:
Lower Bound = 0.565 - (3*3.21) = -9.07
Upper Bound = 3.775 + (3*3.21) = 13.41
The data point for Day 11 (which is $101.20) qualifies as a major outlier.
How to Deal With Outliers
Now that you have identified all your outliers, you should look at each outlier in the context of the other data points in the range, as well as the whole data set. This requires prior knowledge on the nature of the data set, data validation protocols, and the behavior of the variable you are analyzing.
For example, you have the following data points as peak temperature of Delhi (in Celsius) over the past two weeks: 30°, 31°, 28°, 30°, 31°, 33°, 32°, 31°, 300°, 30°, 29°, 28°, 30°, 31°. Day 9 had a peak temperature of 300°C, which is clearly unrealistic.
On the other hand, when you look at the pocket change example, it is not unrealistic to have $101.20 in your pocket. It is possible that you just withdrew $100 from the ATM right before you recorded the data point.
To handle such situations, it is a good practice to have protocols in place to verify each outlier.
If your outlier is verified to be correct, you should leave it untouched. Such an outlier, in fact, emerges as a useful insight from your data set — and is worth looking into.
If the outlier is incorrect, there are two ways to deal with it:
- Resurvey the data point: This is the most foolproof way of dealing with incorrect outliers. Resurveying becomes easier while using mobile-based data collection applications like Collect.
- Delete the outlier data point: Resurveying may not be feasible in all cases due to resource constraints. In such situations, you should delete the outlier data point.
Photo Credit: Mayank Pradhan via Flickr



6 Comments
Great article,
the use of Grubbs test for outliers would also help and quicken outlier identification. I have been using it and it id very effective
Inner Fence:
Lower bound = Q1 – (1.5 * (Q3-Q1))
Upper bound = Q3 (1.5 * (Q3-Q1))
Outer Fence:
Lower bound = Q1 – (3 * (Q3-Q1))
Upper bound = Q3 (3 * (Q3-Q1))
What is 1.5 and 3 here?
Hey Abhishek, the 1.5 and 3 are just numbers that you multiply by the interquartile range (which equals Q3 minus Q1).
In the example above (in “The Statistical Way” section), Q1 is 0.565 and Q3 is 3.775. Then the interquartile range is 3.21 (3.775 – 0.565 = 3.21). Then the inner fence’s lower bound is -4.25 (calculated by plugging the numbers into the equation: 0.565 – (1.5 * 3.21) = 0.565 – 4.815 = -4.25), and so on.
Does that help? You can also check out the sample data set and full example above.
Hi Christine,
It’s helpful. Thanks for the clarification.
[…] Following are examples of simple tools to visualize data and spot outliers: […]
How was the 1.5 gotten