
We thought it would be easy enough to figure this out, but we couldn’t have been more wrong.
At Atlan, we started out as a data team ourselves, driving data projects for social good with organizations like the United Nations, Gates Foundation, the World Bank, etc.
We acted as a “data team” for our customers, so we experienced all the chaos and frustration of dealing with large-scale data firsthand. We were awoken with crisis calls every couple of days for even tiny issues — whether it was troubleshooting why a number on a dashboards was incorrect to trying to get access to the right data set.
We worked with a wide variety of data, everything from 600+ government data sources to unstructured data sources like satellite imagery. Our data grew faster than we expected, and we hadn’t really planned how to store or access it beforehand. We quickly realized we needed a central repository to help our team discover, understand, and build trust in all the data sets we were working with.
We thought it would be easy enough to figure this out, but we couldn’t have been more wrong. Here’s the story of how it took 4 attempts and 5 years to finally succeed in implementing a successful data catalog for our team.
Attempt 1: Build an NLP search powered by a knowledge graph
We first started dabbling with data catalogs back in 2013. We had been working with big government data sets, and it was a pain to organize them and find the information we needed quickly.
Our goal was to create a repository of all our data. We wanted to make it intelligent, easy to search, and intuitive to use. If we got it right, we thought we’d even make it available to our users so they wouldn’t have to go through the same difficult government data websites.
We brought our best data engineers on the project and built an ambitious roadmap — every user who searches should be able to get to the right data in seconds. We invested heavily in setting up the best search algorithm tools like Elasticsearch and graph engines like Neo4j, and even built our own natural language capabilities.
The most exciting demo from our internal team was when they searched for “doctors with fees more than 300 Rs”, and the tool returned an exact answer. Not a list of data sources or tables, but the exact 10 rows from within the most relevant table.
However, despite being one of our most successful technical accomplishments in our 3 attempts building a data catalog, we failed.
Why we failed
The fundamental challenge that stops data catalog projects from taking off isn’t the search algorithm. The search algorithm today is honestly the easier part of the puzzle, having been commoditized by ecosystems like Elasticsearch and SaaS products like Algolia.
The real challenge lies in building relevancy into data discovery — i.e. being able to curate and tag datasets and metadata so that our knowledge graph could build meaningful relationships and our search algorithms could understand what data was actually relevant to a user.
In the last year, there has been a lot of buzz about AI-driven metadata management ecosystems. At Atlan, we’ve spent a lot of time thinking about (and building) ML algorithms to automate whatever is possible for metadata curation — for example, auto-recommendation of column descriptions or relevant business tags from bots. However, amidst all the hype, it is critical to understand what ML can and cannot do.
The very reality of data science and analytics lies at the intersection of technology and business. No data team can be successful without human-led context about business, users, and entities. While machines can help with the process of enriching metadata can be aided by machines, they will never replace humans.
The reason we failed in our first attempt was we focused too much on the cool and jazzy parts of technology, like NLP-powered search, rather than the core challenge — how do we enable our data team to easily add “context” to all our data assets as a part of their daily workflow?
Attempt 2: Buy a data cataloging solution
After investing significant time and engineering resources into that tool, we gave up trying to build an internal solution. Instead, we decided to buy one.
One of our analysts began evaluating all the commercial, off-the-shelf solutions available. She ended up with a list of about 10 products, and we started contacting them.
This started a long three-month process to understand the capabilities of what’s out there, and what’s possible. Many of these vendors didn’t even respond to our request for a demo, probably because we were too small. Some took our calls, but they quoted million dollar fees and 18 month implementation cycles. Most of these products had interfaces that looked like they were built in the 1990s for IT teams. And all of them had complex implementation cycles and licensing models.
This whole process was nerve-wracking for us. We were a modern team that loved investing in productivity.
We were already using Slack, Quip, Github and a dozen other SaaS tools to help our team run better. We were so used to the basics of modern software (quick set-up, small upfront investments, pay-as-you-go models, and delightful user experiences) that we couldn’t believe the only way to solve our data CRM problem was… well, non-existent.
The final straw was when we found what seemed like a relatively new, promising product in the ecosystem. Since their product was still being developed, we sent them a list of a dozen feature requests. They responded that it would cost $20,000 per feature, just to prioritize it in their roadmap.That was $240,000 for developing relatively basic features, not to mention the additional software licensing fees over and above that.
And, so, with that, we shut down our second attempt.
Why we failed
There was no solution available at the time for our type of team — cloud-first, “pay as you go” pricing, fast set-up time, and fewer than 20 users.
Attempt 3: Create a hacky internal tool (and make some progress)
After two full-blown failures, we attempted this project slightly differently. This time, we were… quasi-successful.
We started this attempt slightly differently. Instead of thinking about the product, we started by creating a simple shared metadata framework. This was basically a list of all the attributes we would like to collect as “context” for all of our data. For each data asset, our data analysts and scientists would create this metadata in a .txt file. It was stored in the same shared folder as our data assets (an AWS S3–like object storage), and an extractor would dump it into a central “catalog”. The catalog itself was a simple UI with a basic search and browse functionality.
The good thing about this framework was that basic discovery was available and enabled across all our data assets. However, while this catalog helped improve some data discovery issues for the team, we weren’t very successful in actually getting our team to add context about data assets — i.e. column descriptions, why we dropped certain columns in analysis, verified data assets, and more.
This is when we realized that, when it comes to data, creating shared context is a team sport.
Why? No one person ever has full context about data. Some context is business-focused, so only the business analyst or stakeholder knows it. Some context is technical, known by the data engineer. And some context is buried deep in the data, like weird anomalies in a column, known by the data analyst.
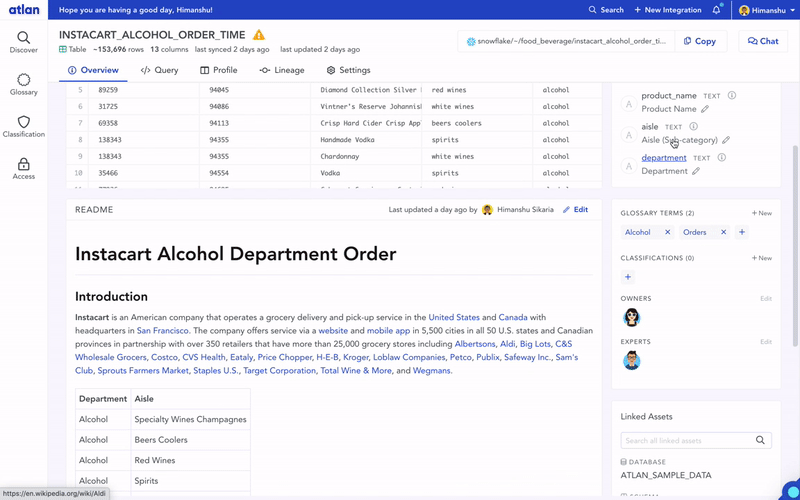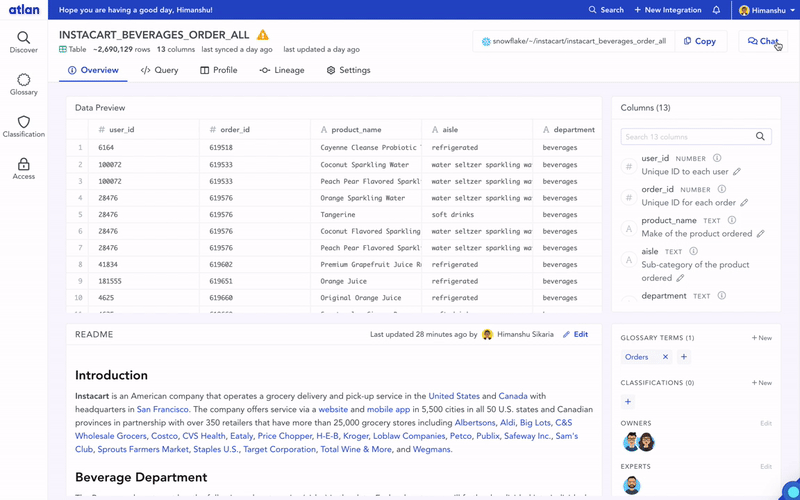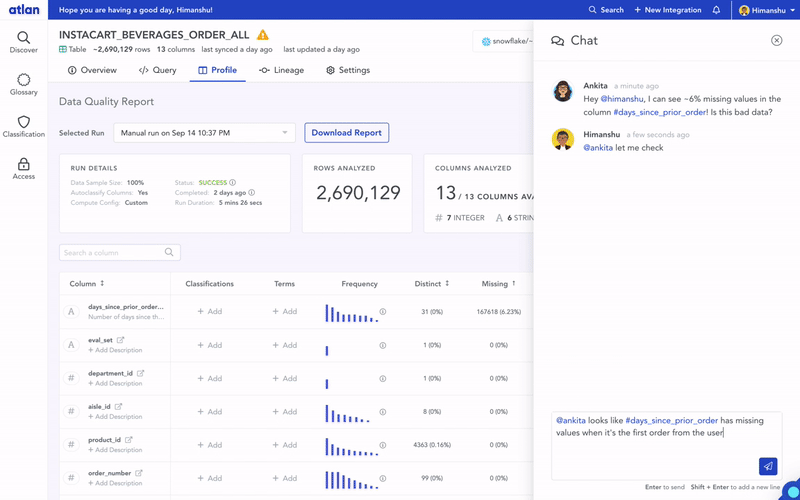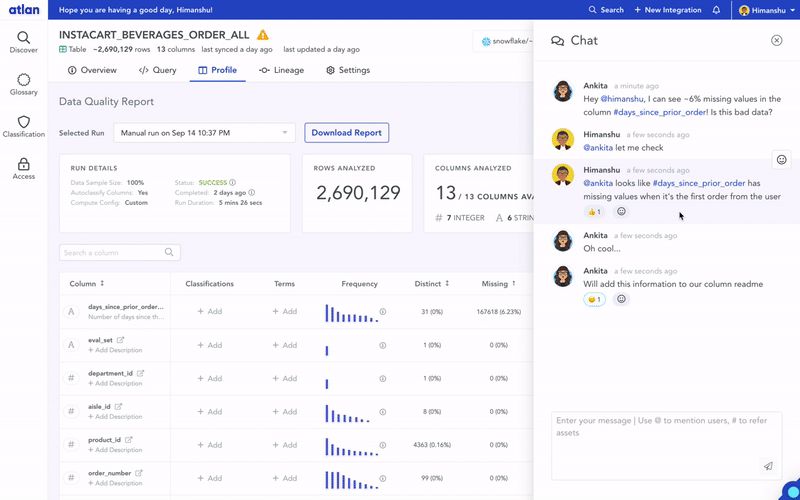
To create true shared context, the right solution needs to be inclusive. On one hand, we needed to make it easy for an engineer to push in metadata via APIs in their pipeline tool. On the other hand, business users needed an easy UI or Slack integration to add their context. Integration with different people’s workflows is where this attempt fell short.
Why we semi-failed
In this project, I think we succeeded at the first step — creating the metadata framework that was most effective for our team. However, we just didn’t focus enough on the next step — creating a user experience that would make it brain-dead easy and intuitive for all our team members to add context to the data assets.
Like most teams, engineering and product resources were scarce. We didn’t have a product designer or UI/UX expert on the project — we simply couldn’t spare the resources. The result was a clunky experience where it was difficult to update metadata. Like most modern teams, our culture would never allow us to “mandate” that people adopt internal tools, and so no matter what we did, we couldn’t actually get people to use this clunky tool.
Attempt 4: Focusing on user experience as the starting point
This time we started off differently, because we couldn’t keep tackling and failing at this problem. We started with an “Analysts Anonymous” session, where our data team got together on a Friday evening and poured their hearts out. They talked about the challenges they were facing and the frustrations they dealt with in their daily work.
We again committed to building our own tool, but nothing hacky this time. Learning from our latest attempt, we started with high-fidelity UI-driven prototypes. We tested them first on ourselves, then on a group of pilot clients across different organization types, cultures, fields, geographies, etc.
We tested and revised repeatedly until our own team and the teams we worked with actually enjoyed using the tool.
This took a long time, but it was worth it. The tools we built helped our own data team double the quality of their work while halving the time we took for data projects. This is the version that has turned into Atlan today.
Why we succeeded
Airbnb said something profound when sharing their learnings about driving adoption of their internal data portal: “Designing the interface and user experience of a data tool should not be an afterthought.” We should have paid attention to this a long time ago.
Our fourth attempt finally worked because we didn’t start with a cool feature, like our first attempt’s NLP-powered search, or the backend functionality, like our third attempt’s hacky tool. We started with the user experience to make something that our team would want to use.
We didn’t have a “cool” NLP powered search (though we’re working on it 😉), but people didn’t care. Our team and customers actually liked using Atlan on a daily basis. They were finally curating, sharing, and collaborating on data, and that’s what matters most.
The future of data catalogs: Collaborative workspaces for diverse data users
In the past year, as Atlan has become a core part of data team workflows, I’ve spent a lot of time thinking about the future of data catalogs.
It has become clear to me that the future of this category will look more like a Github or Figma than anything we see in today’s world. It will borrow principles from Notion and Superhuman, enabling data teams to become more productive through embedded collaboration.
Embedded collaboration is about work happening where you are, with the least amount of friction. Imagine if you could request access to a data asset when you get a link, just like with Google Docs, and the owner could get the request on Slack and approve or reject it right there? No more micro-workflows across countless tools that just waste our time and energy. Just one unified space that’s both inclusive and delightful to use.
Read more about the 4 key principles that will drive the next wave of data catalogs.
This article was originally published in Towards Data Science.


