
Guest blog by Akash Deep Verma from Delhivery.
As the Director of Data Engineering at Delhivery (India’s leading fulfillment platform for digital commerce), I’m surrounded by a huge amount of data. Over 1.2 TB per day, to be exact.
Delhivery fulfills a million packages a day, 365 days a year. Its 24 automated sort centers, 85+ fulfillment centers, 70 hubs, 3,000+ direct delivery centers, 7,500+ partner centers, 15,000+ vehicles and 40,000+ team members run smoothly thanks to a vast network of IoT devices. There are nearly 60,000 data events and messages coming in and going out of our pipelines per second.
With this much data, it’s probably no surprise that data discovery and organization are a big challenge. We finally found our dream data cataloguing solution, but it was no simple task.
At Delhivery, we started our journey with a data catalog in 2019. Over the next year and a half, we considered and invested in several different types of solutions. We evaluated traditional enterprise-focused data catalogs (e.g. Alation, Collibra and Waterline), built our own catalog with Atlas and Amundsen, and later adopted the modern SaaS unified data workspace, Atlan.
In this blog post, I’m unpacking all of my learnings as a lead engineer on this project in the hopes that it helps other data practitioners and leaders who are facing similar challenges and want to successfully implement a modern data catalog.
Why Delhivery desperately needed a data cataloguing solution
As Delhivery has grown over the past decade, the scale and complexity of its data have grown even faster.
Earlier in its history, Delhivery generated 1 TB of data per quarter. Now we’re generating 1.2 TB per day.
That data is organized and processed by hundreds of microservices, which means that ownership over our data is distributed across different teams. Delhivery started with a monolithic system, but we took the call to start forking services about 4 years later as the business scaled exponentially.
Teams soon started building their own microservices, motivated by a desire to make data-driven decisions. Everyone wanted to find and access specific data, so they’d reach out to several developers and ask for help. Later on, we realized that developers were becoming a bottleneck, and we needed a Google Search–style way for anyone to find data through a common portal.
However, finding data wasn’t the only issue. Once teams got hold of the data they wanted, they struggled to understand it. There wasn’t a clear way to organize our data and add important information and business context. This quickly became clear throughout our onboarding process — the typical time to onboard a new team member was 1–2 months, but this process eventually grew to 3–4 months as Delhivery and its data kept growing.
By 2019, we realized we desperately needed a data cataloguing solution, one where people could navigate through all our data, look for whatever they need, check what a data asset looks like, build a better understanding of other domains or teams within the company, and even add their own info or context about a data asset.
Step 1: Evaluating available commercial data catalog solutions in the market
We started off our search for a data catalog by evaluating commercial products like Alation, Waterline (now called Lumada) and Collibra. We dove deep into their specs and compared them on two main criteria:
- Features: Did the product have all the features we needed?
- TCO: What was the total cost of ownership (i.e. the purchase price plus other costs like set-up or operations)? Did it fit with our budget?
Buying one of these products would have been the simplest fix, but unfortunately we couldn’t find the right solution. Each one was either missing non-negotiable features (such as seeing a data preview or querying data) or the TCO was just too high for us (due to expensive set-up, licensing and professional service fees).
We didn’t want to settle for something that wasn’t quite right, since setting up a data catalog is a huge commitment. So we realized we needed to build and customise our own internal solution.
Step 2: Building our first data catalog with Apache Atlas and Amundsen
To set up our first data catalog, we kicked off an internal project with two developers. They worked full-time for seven months to develop and customise a data cataloguing solution based on open-source software.
After researching different options, we decided to use Apache Atlas as the backbone of our metadata management framework.
We chose Atlas mainly because of its available features. As a bonus, we also liked that it was widely used, actively in development, backed by Apache and supported by the entire Apache community.
However, as we started implementing Atlas, we realised we had a problem. Atlas is great for developers, but it has a steep learning curve for non-technical team members. We found its interface and language was highly technical, which made it difficult to onboard product managers or operations people who needed to understand our data. In short, Atlas had the features we needed, but it wasn’t right for our end users.
To solve this, we decided to bring in Amundsen. Started at Lyft and advertised as “Google search for data”, Amundsen is a data discovery service that became the search interface for our Atlas backend.
Step 3: Developing missing features on top of Amundsen and Atlas
As we implemented and tested our open-source data catalog, we realized that Atlas and Amundsen still didn’t have all the features we needed. So we started modifying our solution and developing new features on top of it.Here are a few of the features that we built for our internal data catalog:
- Searching on columns, rather than the default option of searching on tables
- Better search organisation, based on custom criteria like popularity or relevance
- Displaying whether columns that appear in search have already been cleaned
- Improving how columns on a data asset’s detail page are organised to improve relevance
- Showcasing data quality with Markdown and APIs
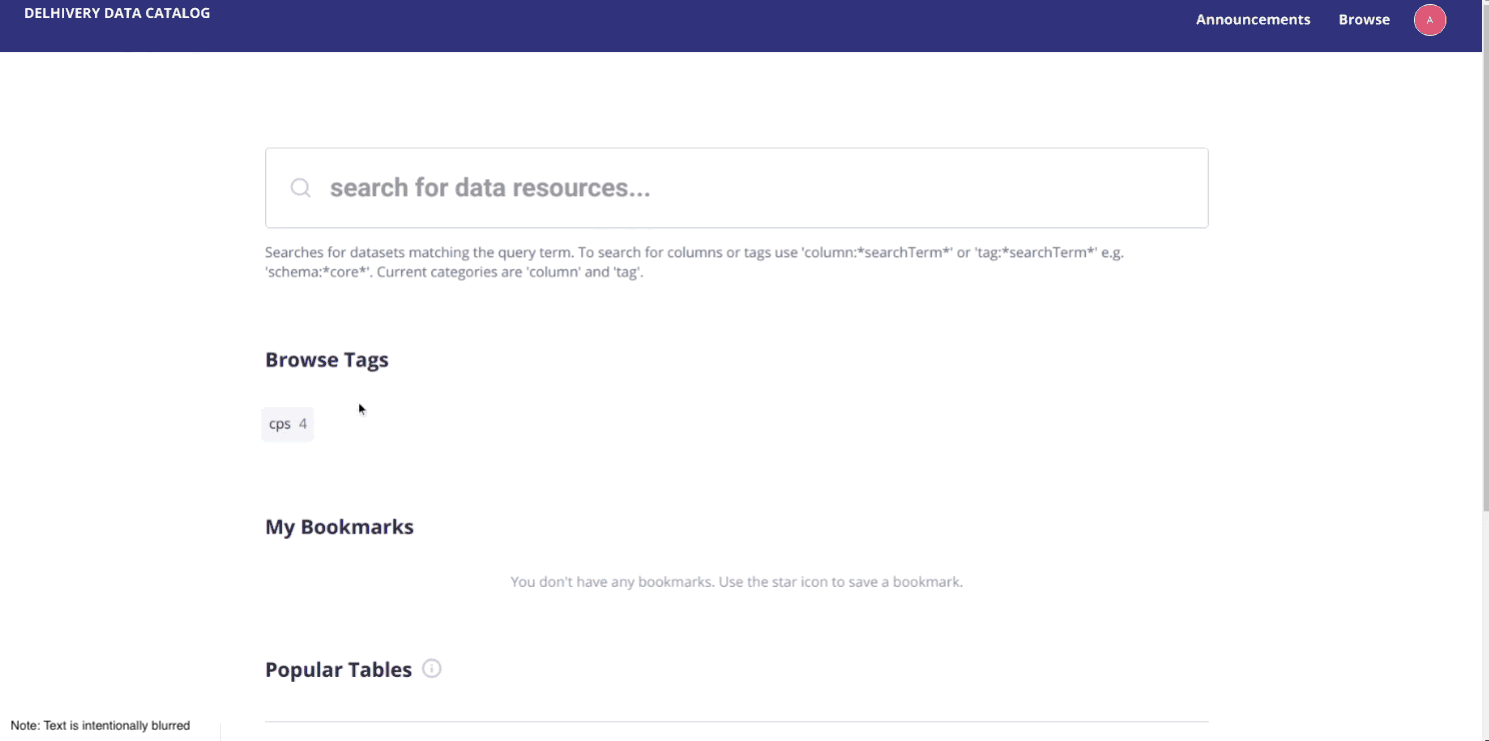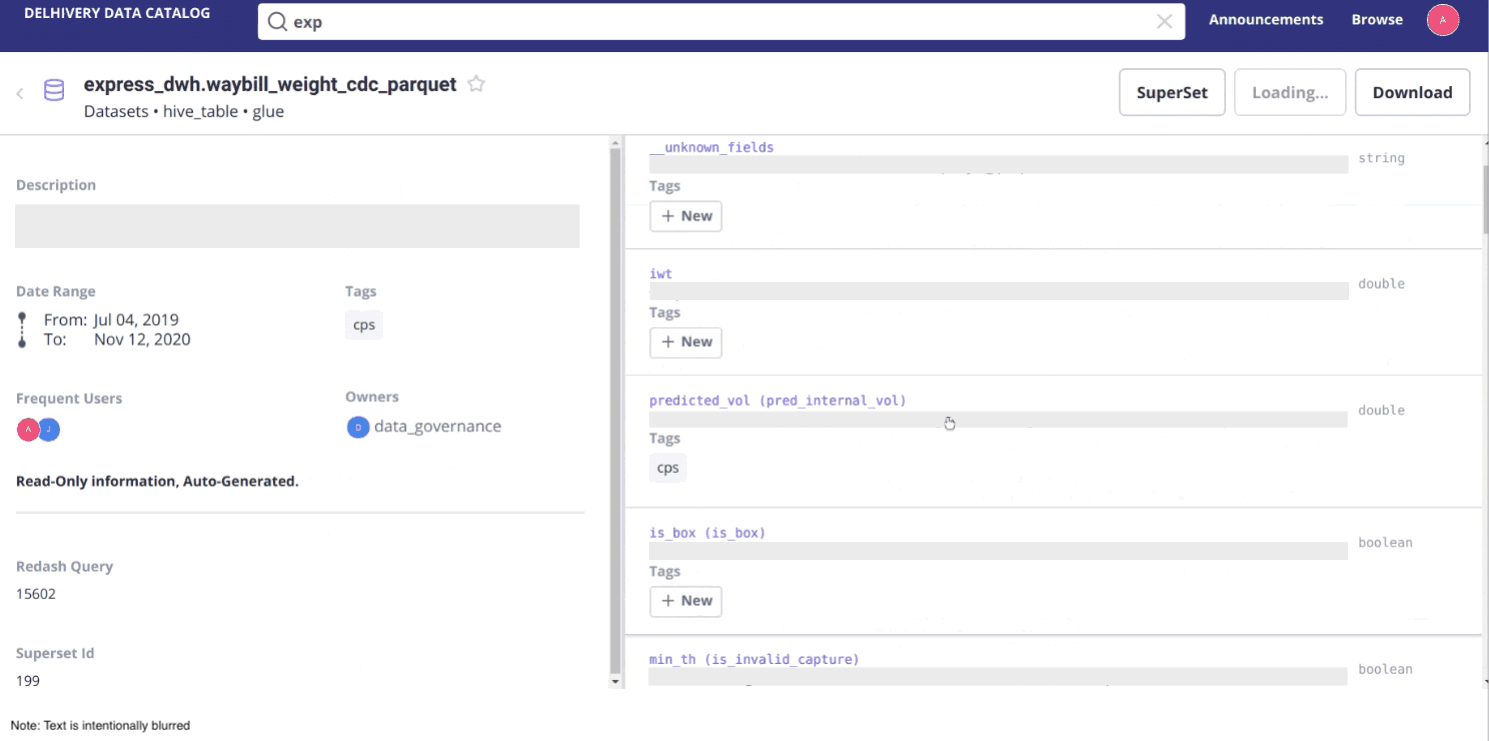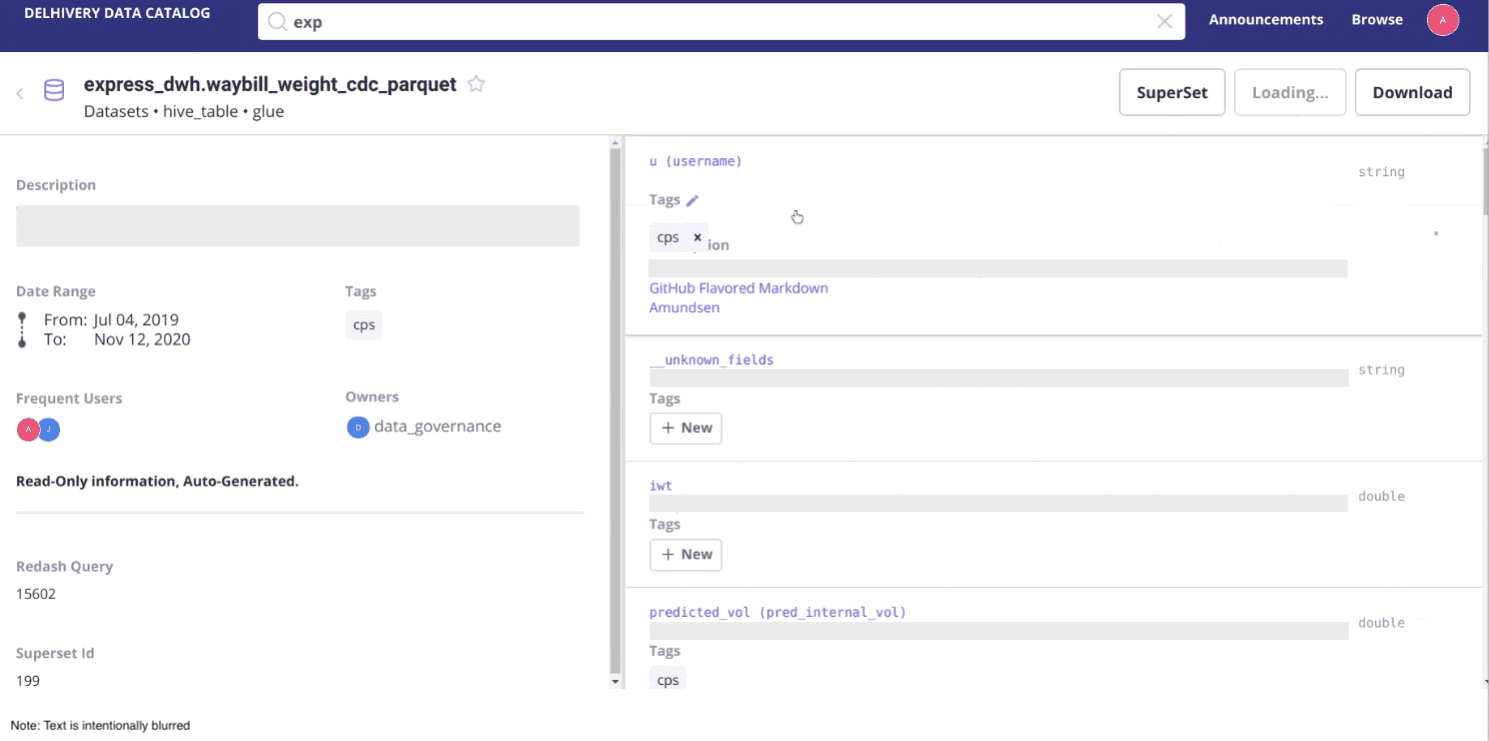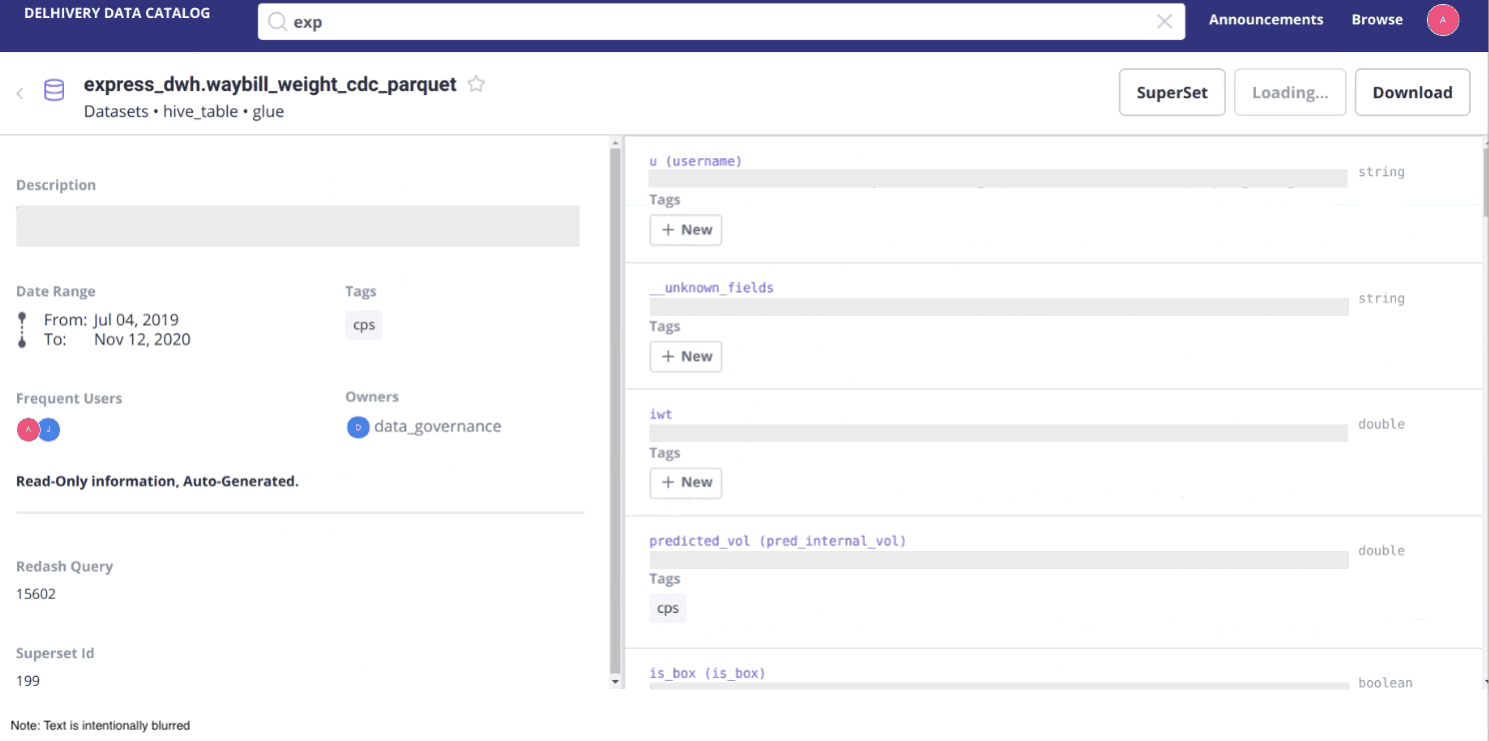
Step 4: Rolling out version 1 of our data catalog to the end users
After selecting Atlas and Amundsen, setting them up and developing our own features on top of them, we finally finished our first data catalog. We rolled it out to the company, but we quickly struggled with getting people to use it.
Initially, team members were excited to use the new data catalog. But after logging in a few times, they just didn’t return. It didn’t become a habit, something that they would use continuously.
When we asked people what was missing, they all pointed to the user experience. The key problem was that they felt like they weren’t able to grab hold of the catalog and integrate it into their daily work.
We had created our catalog with two developers, no UI or UX designers involved. We thought that was fine since the design and layout had already been fully thought-out by Amundsen.
We underestimated the importance of user experience. It plays a crucial role in driving data culture, and our solution couldn’t win without creating an experience that people wanted to use every day.
Step 5: Back to the drawing board…
After seven months of development, we weren’t much farther than where we started. Even though we had invested so much time and energy in our open-source data catalog, it wasn’t right. Time to go back to the drawing board and figure out our next move…
After some thinking and a new roadmap, we realised that fixing our current solution wouldn’t be easy. User experience was key, so we couldn’t succeed without lots of hard work on our interface. We would need a full product team — UI/UX designers, product managers and engineers — to revise our data catalog so our colleagues would actually use it.
At the same time, we started researching commercial options. Yes, we had looked into these products before, but the data catalog market had seen a ton of innovation in the 18 months since our earlier research. So we started our search again, finding and evaluating the latest commercial data cataloguing products. That’s when we found Atlan.
Step 6: Choosing Atlan as our unified data workspace
Atlan is a modern data workspace that excels at data cataloguing and discovery, but it is much more than just a traditional data catalog. In our research, we found it to be the best solution for our company.
The Atlan team actually started as a data team themselves, and they built Atlan internally for their work. This has driven their collaboration and user experience–focused approach, making it closer to a Github or Figma-like experience for data.
Atlan not only had all the dream features we were looking for, but the user interface and experience were extremely intuitive. Built around a Google-style search, Atlan was designed to be user-friendly for technical and non-technical users alike. Its collaboration-first approach — e.g. the ability to share data assets as links, or its integrations with Slack — was also very promising. When we gave Atlan to team members, they were able to get onboarded and start driving things very quickly.
We also liked that Atlan has a fundamentally open philosophy. It was built on open-source (Apache Atlas and Ranger) with an open API backbone. This gave us the ability to build on top of Atlan and customise the product for our end users — bringing together the best of open-source with a polished, off-the-shelf user experience.
When we had compared our roadmap with commercial products, we realised that the time we had already sunk into our open-source solution didn’t matter.
It would take six or seven people and up to two years to build what Atlan gave us out of the box. We needed a solution on day zero, not in a year or two.
As counterintuitive as it seemed, we realised that buying a data cataloguing product would be a lower TCO than continuing to build our own. We set aside our internal catalog and said a big yes to Atlan.
We also decided to go with Atlan because we realised that we needed a partner who was an expert in data discovery. This would let us rely on their expertise as we rolled out our solution within the company. We were happy to let them be the experts in data cataloguing — we had plenty of our own business problems to tackle.
The workshop sessions that Atlan conducted during our Proof of Concept also helped us feel sure that we were partnering with the right solution and team. These continuous workshops helped us onboard new team members, dive deep into advanced features, and maintain traction as team members started documenting data and filling our new metadata stores.
Some final thoughts on our build-vs-buy adventure
I’ve been on this wild data cataloguing journey for the past year and a half. There have been plenty of ups and downs, but I’m excited about where we’ve ended up. I think we’ve finally found the right platform to make our data self-service, discoverable and clear for our data-driven teams.
The other day, someone asked me what I’d do differently if I was to start all over again. I realised I had two big learnings.
First, user experience is key. Figure out the end consumers of your data — whether they’re product managers, engineers or operations people — and their daily use cases. What data-driven decisions are they making? How do they find data, and what information do they need about it? How can you remove frustrating bottlenecks like reaching out to developers? Focusing on your users’ needs upfront can save you from shelving a functional but poorly designed solution like us. Remember, if your end users are not developers, then ease of use and intuitiveness is key.
Second, start early with data discovery and cataloguing. Instead of waiting until data discovery becomes a problem, it’s much better to start on day one. This lets you scale your process and solution as your company and data scale, rather than having to shoehorn a new product into years of established workflows.
Image credit: Header photo by CHUTTERSNAP on Unsplash.


