
These trends have converged to create a storm around a new, modern idea of metadata.
Last year, we hit some major landmarks in the world of metadata. Gartner scrapped its Magic Quadrant for Metadata Management, companies started asking for third-generation data catalogs, and modern metadata companies (like mine!) launched and raised some serious VC money.
All of this actually prompted me to add metadata as one of my six key data ideas for this year.
But why is metadata such a hot topic in the data world now? What’s behind all of this hype?
In this article, I’ll break down the five trends behind this new world of metadata. Some kicked off over half a decade ago, while some are just months old — and today they’ve converged to create a storm around a new, modern idea of metadata.
TL;DR: The five trends
- The modern data stack went mainstream, featuring a full range of unprecedented fast, flexible, cloud-native tools. The problem — metadata has been left out.
- Data teams are more diverse than ever, leading to chaos and collaboration overhead. Context is key, and metadata is the solution.
- Data governance is being reimagined from top-down, centralized rules to bottom-up, decentralized initiatives — which requires a similar reimagining for metadata platforms.
- As metadata is becoming big data, the metadata lake has infinite use cases for today and tomorrow.
- Passive metadata systems are being scrapped in favor of active metadata platforms.
1. The creation of the modern data stack
Starting around 2016, the modern data stack went mainstream. This refers to a flexible collection of tools and capabilities that help businesses today store, manage, and use their data.
These tools are unified by three key ideas:
- Self-service for a diverse range of users
- “Agile” data management
- Cloud-first and cloud-native
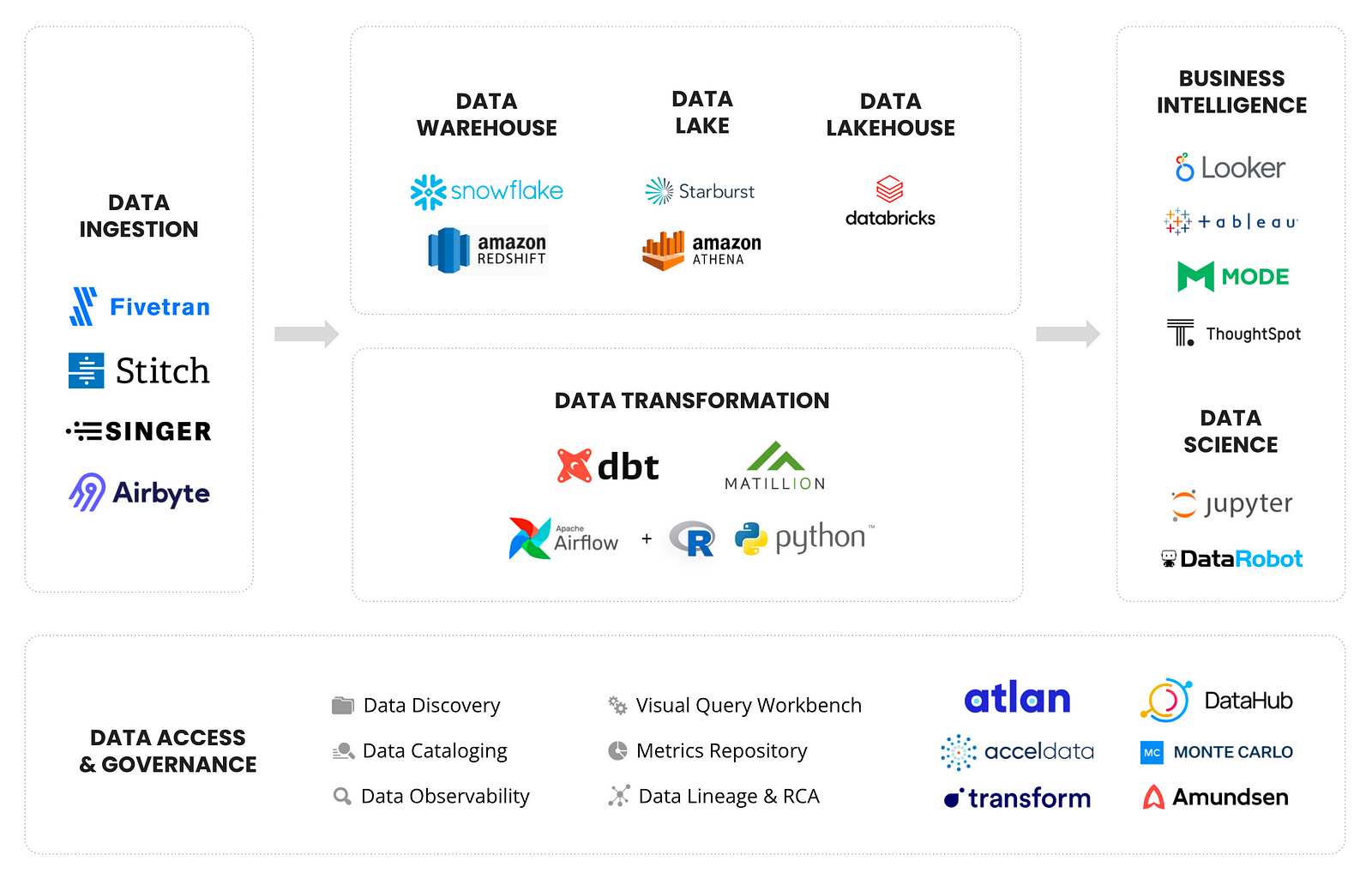
Today’s modern data stack is easy to set up, pay as you go, and plug and play — people won’t put up with anything else these days! Tools like Fivetran and Snowflake let users set up a data warehouse in less than 30 minutes.

In an ecosystem of increasingly easy, fast, interconnected data tools, the old idea of metadata — passive, siloed data inventories, powered by an army of data stewards — just doesn’t cut it anymore. Many of the earlier second-generation data catalogs still need significant engineering time for setup, not to mention at least five calls with a sales representative to get a demo. So is anyone surprised that the data world is eagerly searching for a better way to handle metadata?
Read more about the modern data stack.
2. The diverse humans of data
A few years ago, only the “IT team” would get their hands dirty with data.
However, today’s data teams are more diverse than ever before. They include data engineers, analysts, analytics engineers, data scientists, product managers, business analysts, citizen data scientists, and more. Each of these people has their own favorite, equally diverse data tools — everything from SQL, Looker, and Jupyter to Python, Tableau, dbt, and R.
This diversity is both a strength and a struggle.

All of these people have different tools, skill sets, tech stacks, work styles, and ways of approaching a problem… Essentially, they each have a unique “data DNA”. More diverse perspectives mean more opportunities for creative solutions and out-of-the-box thinking. However, it also usually means more chaos within collaboration.
This diversity also means that self-service is no longer optional. Modern data tools need to be intuitive for a wide range of users with a wide range of skill sets. If someone wants to bring data into their work, they should be able to easily find the data they need without having to ask an analyst or file a request.
Metadata is emerging as the solution to these challenges. As Benn Stancil wrote, “Today’s data stack is quickly fracturing into smaller and more specialized pieces, and we need something that binds it all together.” His answer to this is metadata. Metadata is evolving to provide critical context as we continue to bring an increasingly diverse set of people and tools into our data ecosystem.
Read more about the humans of data.
3. The new vision for data governance
Data governance is seen as a bureaucratic, restrictive process — a set of rules dropped down from on high to slow down your work. And the reality is, that’s often how it actually works.
Companies surround their data with complex security processes and restrictions, all dictated by a distant data governance team.
However, as the modern data stack has made it easier to ingest and transform data, this idea of data governance has become one of the biggest barriers in daily data work.
For the first time, the need for governance is being felt bottom-up by practitioners, instead of being enforced top-down due to regulation. That’s why data governance is currently in the middle of a paradigm shift.

Today, governance is becoming something that the humans of data embrace rather than fear. At its heart, it’s now less about control, and more about helping data teams work better together.
As a result, data governance is being reimagined as a set of collaborative best practices by and for amazing data teams — ones that are about empowering and creating better data teams, not controlling them.
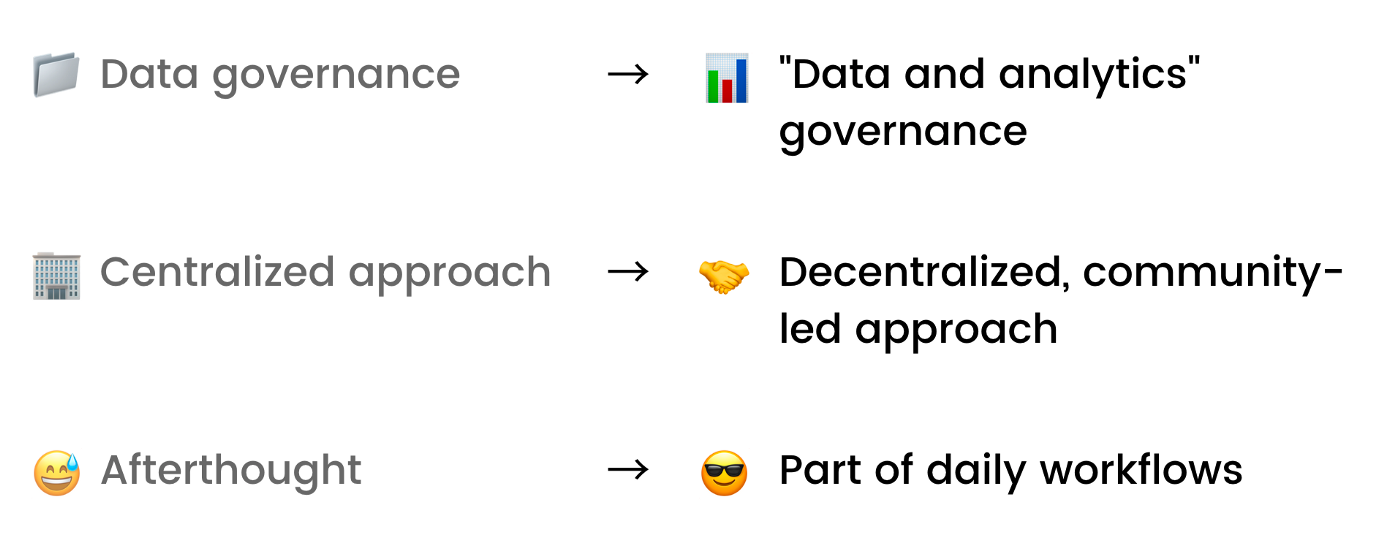
Modern, community-led data governance needs a whole new kind of metadata management platform. For example, the old way of top-down, steward-based data management processes won’t work anymore. Tools need to adapt to allow data users to crowdsource context as a part of their daily workflows in Slack or Microsoft Teams. Another key aspect involves using metadata to automate data classification, such as auto-classifying and restricting access to assets with PII data.
Read more about modern data governance.
4. The rise of the metadata lake
In 2005, more data was being collected than ever before, with more ways to use it than a single project or team could dream of. Data had limitless potential, but how can you set up a data system for limitless use cases? That led to the birth of the data lake.
Today, metadata is at the same place. Metadata is itself becoming big data, and technical advances (i.e. elasticity) in compute engines like Snowflake and Redshift make it possible to derive intelligence from metadata in a way that was unimaginable even a few years ago.
As metadata increases, and the intelligence we can derive from it increases, so too does the number of use cases that metadata can power.
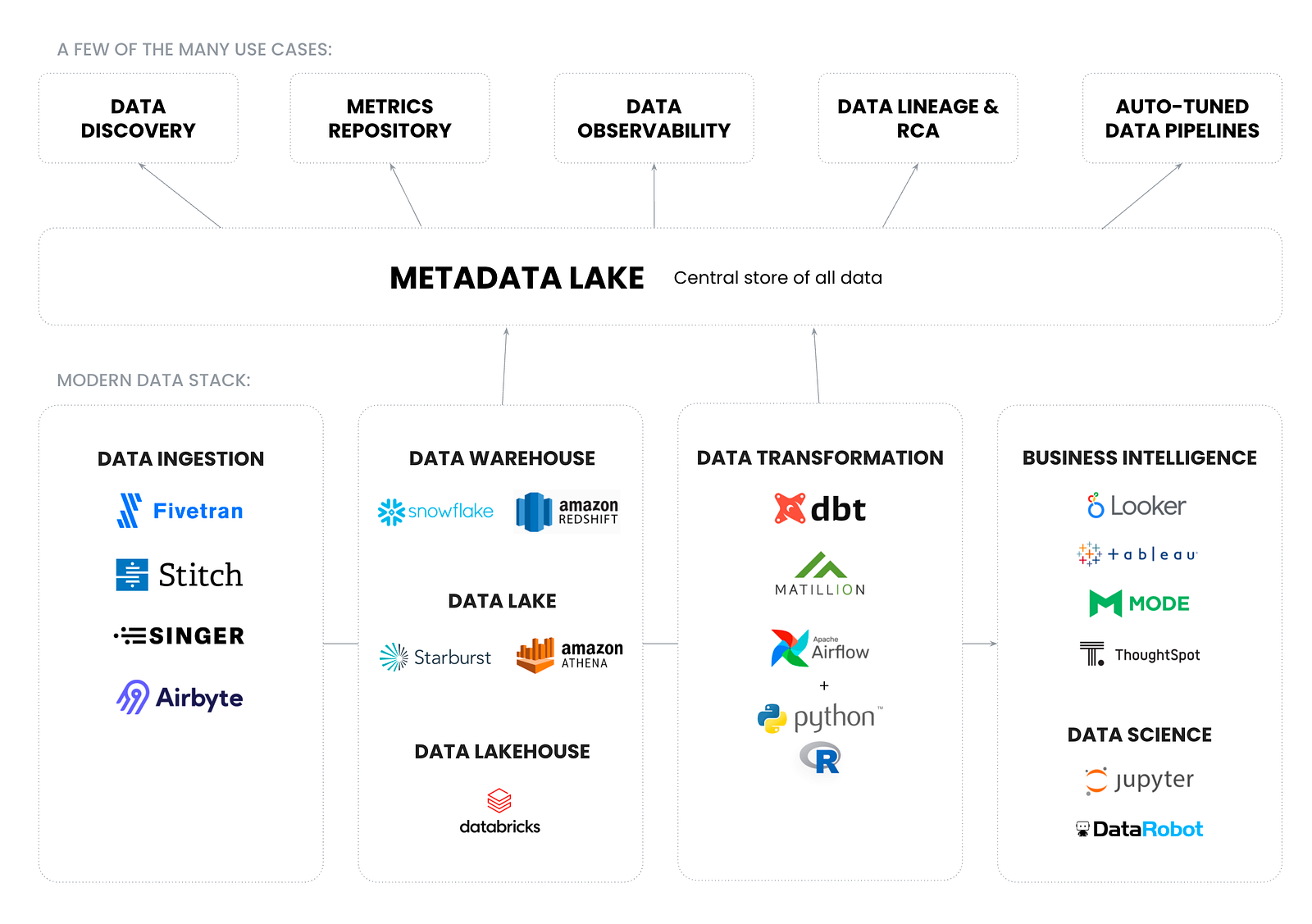
Today, even the most data-driven organizations have only scratched the surface of what is possible with metadata. However, metadata is on the cusp of fundamentally changing how our data systems operate. The metadata lake is what makes this possible.
A metadata lake is a unified repository that can store all kinds of metadata, in both raw and further processed forms, in a way that can be shared with other tools in the data stack to drive both the use cases we know of today and those of tomorrow.
Just like data became far easier to use with data lakes, the metadata lake allows us to finally understand how we’ll be able to use today’s deluge of metadata.
Read more about the metadata lake.
5. The birth of active metadata
In August 2021, Gartner scrapped its Magic Quadrant for Metadata Management and replaced it with the Market Guide for Active Metadata Management. This marked the end of the traditional approach to metadata management and kicked off a new way of thinking about metadata.

Traditional data catalogs are passive. They are fundamentally static systems that don’t drive any action and rely on human effort to curate and document data.
However, an active metadata platform is an always-on, intelligence-driven, action-oriented system.
- Always-on: Rather than waiting for humans to manually enter metadata, it continuously collects metadata from logs, query history, usage stats, etc.
- Intelligence-driven: It constantly processes metadata to connect the dots and create intelligence, such as automatically creating lineage by parsing through query logs.
- Action-oriented: Instead of being passive observers, these systems drive recommendations, generate alerts, and operationalize intelligence in real time.
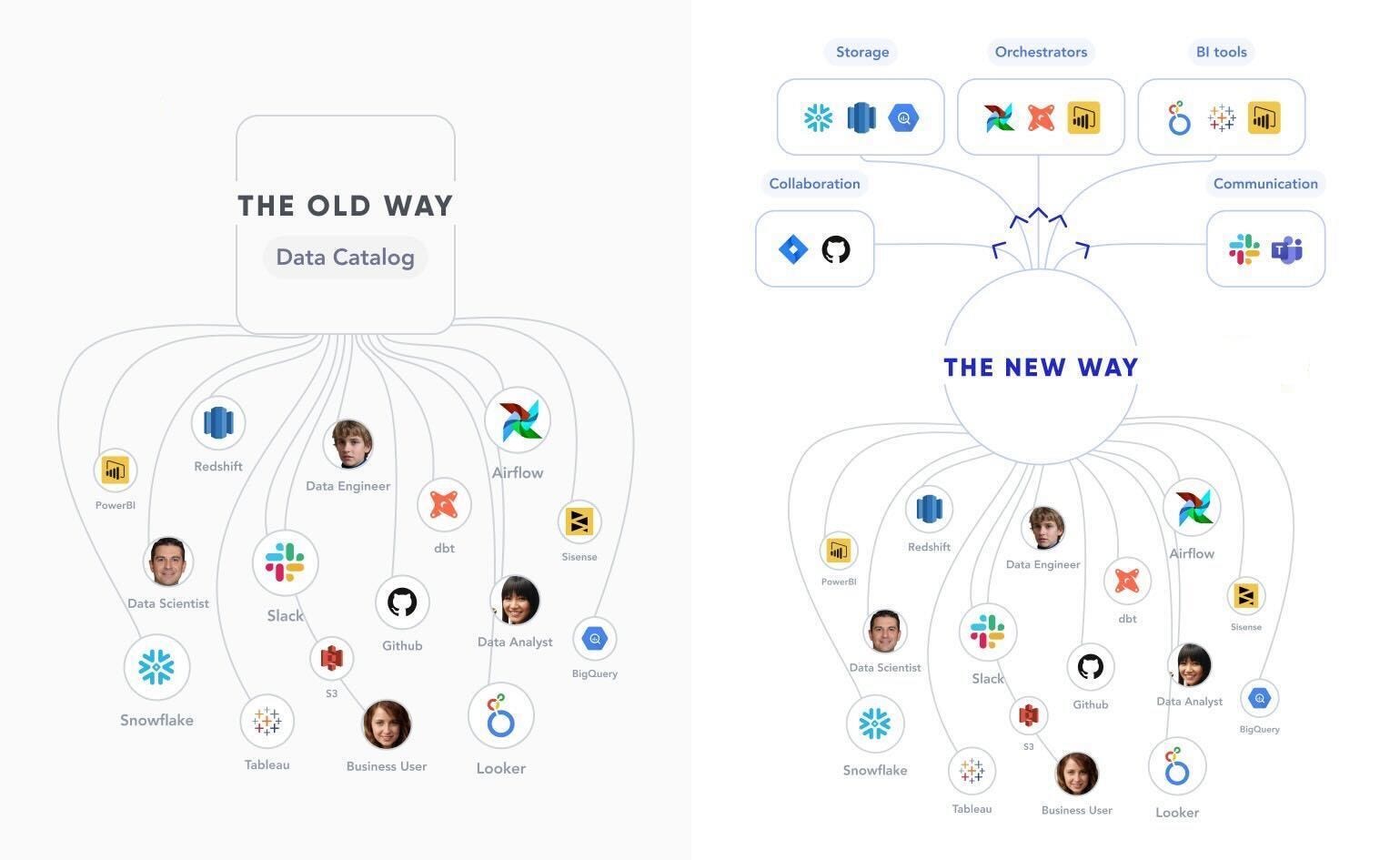
Active metadata platforms act as two-way platforms — they not only bring metadata together into a single store like a metadata lake, but also leverage “reverse metadata” to make metadata available in daily workflows.
Read more about active metadata.
Looking forward
It’s easy to complain about the state of metadata. But when I look back on where it was even five years ago, it’s amazing how far we’ve come.
Thanks to the convergence of these five big trends, we’re at an inflection point in metadata management — a shift from old-school, passive tools to modern, active metadata that powers our entire data stack.
No longer static documentation, metadata holds the key to unlocking our dream of a truly intelligent data management system. We have a ways to go, but I personally can’t wait to see what the next year holds for metadata.
This article was originally published on Towards Data Science.
Header image: Pietro Jeng on Unsplash


